In the last article I have shown how to work with Neo4j in .NET. The article was based on a tiny dataset, which makes it impossible to draw any conclusions about the performance of Neo4j at a larger scale.
In this article I want to see how to import larger datasets to Neo4j and see how the database performs on complex queries.
The source code for this article can be found in my GitHub repository at:
The Plan: Analyzing the Airline On Time Performance
The plan is to analyze the Airline On Time Performance dataset, which contains:
[...] on-time arrival data for non-stop domestic flights by major air carriers, and provides such additional items as departure and arrival delays, origin and destination airports, flight numbers, scheduled and actual departure and arrival times, cancelled or diverted flights, taxi-out and taxi-in times, air time, and non-stop distance.
The data spans a time range from October 1987 to present, and it contains more than 150 million rows of flight informations. It can be obtained as CSV files from the Bureau of Transportation Statistics Database, and requires you to download the data month by month.
More conveniently the Revolution Analytics dataset repository contains a ZIP File with the CSV data from 1987 to 2012.
About the Graph Model
The Graph model is heavily based on the Neo4j Flight Database example by Nicole White:
(:Airport {airport_id, abbr, name})
(:City {name})
(:State {code, name})
(:Country {name, iso_code})
(:Carrier {code, description})
{:Flight {flight_number, year, month, day, })
(:Aircraft {tail_number})
(:Reason {code, description})
(:City)-[:IN_COUNTRY]→(:Country)
(:State)-[:IN_COUNTRY]→(:Country)
(:City)-[:IN_STATE]→(:State)
(:Airport)-[:IN_CITY]→(:City)
(:Flight)-[:ORIGIN {taxi_time, dep_delay} | :DESTINATION {taxi_time, arr_delay}]→(:Airport)
(:Flight)-[:CARRIER]→(:Carrier)
(:Flight)-[:CANCELLED_BY|:DELAYED_BY {duration}]→(:Reason)
(:Flight)-[:AIRCRAFT]→(:Aircraft)
You can find the original model of Nicole and a Python implementation over at:
She also posted a great Introduction To Cypher video on YouTube, which explains queries on the dataset in detail:
Project Structure
On a high-level the Project looks like this:
Neo4jExample
Core- Contains infrastructure code for serializing the Cypher Query Parameters and abstracting the Connection Settings.
CsvConverter- Converters for parsing the Flight data. The dataset requires us to convert from
1.00to a boolean for example.
- Converters for parsing the Flight data. The dataset requires us to convert from
Mapper- Defines the Mappings between the CSV File and the .NET model.
Model- Defines the .NET classes, that model the CSV data.
Parser- The Parsers required for reading the CSV data.
GraphClient- The Neo4j Client for interfacing with the Database.
Model- Defines the .NET classes, that model the Graph.
Neo4jExample.ConsoleApp
The Neo4j.ConsoleApp references the Neo4jExample project. It uses the CSV Parsers to read the CSV data, converts the flat
CSV data model to the Graph model and then inserts them using the Neo4jClient. Reactive Extensions are used for batching the
entities.
In the end it leads to very succinct code like this:
private static void InsertFlightData(Neo4JClient client)
{
// Create Flight Data with Batched Items:
foreach (var csvFlightStatisticsFile in csvFlightStatisticsFiles)
{
Console.WriteLine($"Starting Flights CSV Import: {csvFlightStatisticsFile}");
GetFlightInformation(csvFlightStatisticsFile)
// As an Observable:
.ToObservable()
// Batch in 1000 Entities / or wait 1 Second:
.Buffer(TimeSpan.FromSeconds(1), 1000)
// Insert when Buffered:
.Subscribe(records =>
{
client.CreateFlights(records);
});
}
}
The Airline On Time Performance of 2014
I decided to import the Airline Of Time Performance Dataset of 2014:
// Use the 2014 Flight Data:
private static readonly string[] csvFlightStatisticsFiles = new[]
{
"D:\\datasets\\AOTP\\ZIP\\AirOnTimeCSV_1987_2017\\AirOnTimeCSV\\airOT201401.csv",
"D:\\datasets\\AOTP\\ZIP\\AirOnTimeCSV_1987_2017\\AirOnTimeCSV\\airOT201402.csv",
"D:\\datasets\\AOTP\\ZIP\\AirOnTimeCSV_1987_2017\\AirOnTimeCSV\\airOT201403.csv",
"D:\\datasets\\AOTP\\ZIP\\AirOnTimeCSV_1987_2017\\AirOnTimeCSV\\airOT201404.csv",
"D:\\datasets\\AOTP\\ZIP\\AirOnTimeCSV_1987_2017\\AirOnTimeCSV\\airOT201405.csv",
"D:\\datasets\\AOTP\\ZIP\\AirOnTimeCSV_1987_2017\\AirOnTimeCSV\\airOT201406.csv",
"D:\\datasets\\AOTP\\ZIP\\AirOnTimeCSV_1987_2017\\AirOnTimeCSV\\airOT201407.csv",
"D:\\datasets\\AOTP\\ZIP\\AirOnTimeCSV_1987_2017\\AirOnTimeCSV\\airOT201408.csv",
"D:\\datasets\\AOTP\\ZIP\\AirOnTimeCSV_1987_2017\\AirOnTimeCSV\\airOT201409.csv",
"D:\\datasets\\AOTP\\ZIP\\AirOnTimeCSV_1987_2017\\AirOnTimeCSV\\airOT201410.csv",
"D:\\datasets\\AOTP\\ZIP\\AirOnTimeCSV_1987_2017\\AirOnTimeCSV\\airOT201411.csv",
"D:\\datasets\\AOTP\\ZIP\\AirOnTimeCSV_1987_2017\\AirOnTimeCSV\\airOT201412.csv",
};
After running the Neo4jExample.ConsoleApp the following Cypher Query returns the number of flights in the database:
$ MATCH (f:Flight) RETURN count(*)
╒══════════╕
│"count(*)"│
╞══════════╡
│5819811 │
└──────────┘
Benchmark Configuration
Take all these figures with a grain of salt.
- The machine I am working on doesn't have a SSD.
- I did not parallelize the writes to Neo4j.
- I didn't change the Neo4j configuration.
- Keep in mind, that I am not an expert with the Cypher Query Language, so the queries can be rewritten to improve the throughput.
Neo4j
The following Neo4j Version was used:
- Neo4j Community 3.3.4
- Neo4j.Driver 1.6.0-rc1
Hardware
The following hardware was used:
- Intel (R) Core (TM) i5-3450
- Hitachi HDS721010CLA330 (1 TB Capacity, 32 MB Cache, 7200 RPM)
- 16 GB RAM
Conclusions
First of all: I really like working with Neo4j! It is very easy to install the Neo4j Community edition and connect to it with the official .NET driver. Neo4j has a good documentation and takes a lot of care to explain all concepts in detail and complement them with interesting examples.
Neo4j Browser
The Neo4j Browser makes it fun to visualize the data and execute queries. You can bookmark your queries, customize the style of the graphs and export them as PNG or SVG files. The built-in query editor has syntax highlightning and comes with auto- complete functionality, so it is quite easy to explore the data.
Write-Performance
I was able to insert something around 3.000 nodes and 15.000 relationships per second:
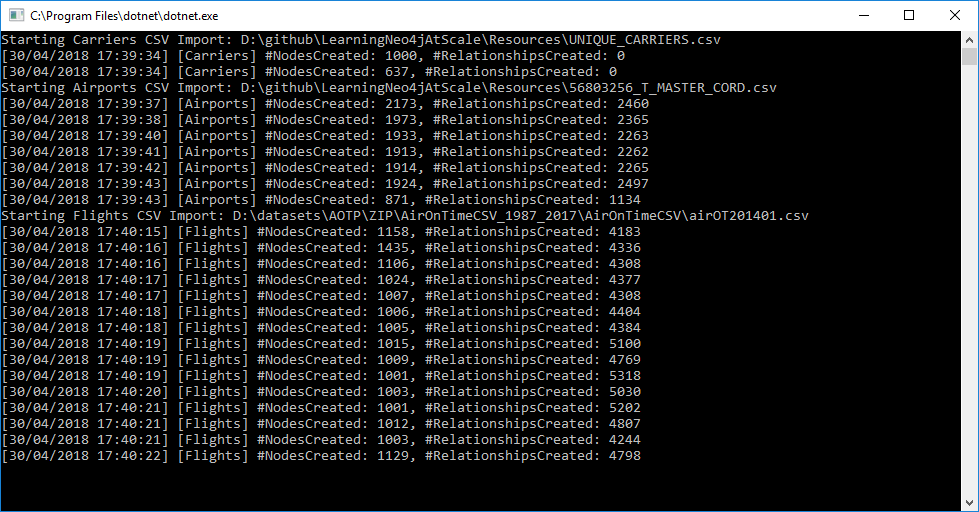
I am OK with the performance, it is in the range of what I have expected.
I am sure these figures can be improved by:
- Rewriting my Cypher Queries.
- Parallelizing inserts.
- Performance Tuning the Neo4j configuration.
But this would be follow-up post on its own.
Read-Performance
Again I am OK with the Neo4j read performance on large datasets. Getting the ranking of top airports delayed by weather took 30 seconds on a cold run and 20 seconds with a warmup. I wouldn't call it lightning fast:
MATCH (f:Flight)-[:ORIGIN]->(a:Airport)
WITH a, COUNT(f) AS total
MATCH (a)<-[:ORIGIN]-(:Flight)-[:DELAYED_BY]->(:Reason {description:'Weather'})
WITH a, total, COUNT(a.abbr) AS num
RETURN a.abbr + ' - ' + a.name AS Airport, ((1.0 * num) / total) * 100 AS Percent
ORDER BY Percent DESC
LIMIT 10
Again I am pretty sure the figures can be improved by using the correct indices and tuning the Neo4j configuration. But this would be a follow-up post on its own:

If you have ideas for improving the performance, please drop a note on GitHub.
Cypher Query Language
The Cypher Query Language is being adopted by many Graph database vendors, including the SQL Server 2017 Graph database. So it is worth
to learn it. The language itself is pretty intuitive for querying data and makes it easy to express MERGE and CREATE operations.
UNWIND
I am not an expert in the Cypher Query Language and I didn't expect to be one, after using it for two days. But for writing the flight data to Neo4j was complicated and involved some workarounds. Or maybe I am not preparing my data in a way, that is a Neo4j best practice?
For example an UNWIND on an empty list of items caused my query to cancel, so that I needed this workaround:
UNWIND (CASE row.delays WHEN [] THEN [null] else row.delays END) as delay
OPTIONAL MATCH (r:Reason {code: delay.reason})
FOREACH (o IN CASE WHEN r IS NOT NULL THEN [r] ELSE [] END |
CREATE (f)-[fd:DELAYED_BY]->(r)
SET fd.delay = delay.duration
)
Creating Optional Relationships
Another problem I had: Optional relationships.
I understand, that a query quits when you do a MATCH without a result. There is an OPTIONAL MATCH operation, which either returns the
result or null if no matching node was found. But here comes the problem: If I do a CREATE with a null value, then my query throws
an error and there is nothing like an OPTIONAL CREATE.
To fix this I needed to do a FOREACH with a CASE. The CASE basically yields an empty list, when the OPTIONAL MATCH yields null.
So the CREATE part will never be executed. Only when a node is found, we will iterate over a list with the matching node. This wasn't really
a straightforward one:
OPTIONAL MATCH (r:Reason {code: row.cancellation_code})
FOREACH (o IN CASE WHEN r IS NOT NULL THEN [r] ELSE [] END |
CREATE (f) -[:CANCELLED_BY]->(r)
)