Table of contents
What we are going to build
In this series I am starting to build "flink-jam", which is a simplified system for detecting traffic congestion, based on Open Street Map and Apache Flink. In the grand vision I want to expand on it, but I am not sure, where this is going. Maybe it ends up a failed experiment?
First things first: Postgis
This sounds like a lot of geospatial data has to be processed. PostGIS is a simple way to store and query geospatial data and it is well integrated with the Open Street Map ecosystem, which is what we are going to use for the map data. Instead of installing it, we will host it in a Docker container.
We need the tags for each osm object, so the hstore extension has to be activated.
Let's add a small SQL script sql/01-enable-hstore.sql to enable it:
CREATE EXTENSION hstore;
And then we can write this super complicated docker-compose.yml for booting a PostGIS instance:
version: '3.8'
services:
db:
image: postgis/postgis:16-3.4
container_name: postgis_db
environment:
POSTGRES_USER: postgis
POSTGRES_PASSWORD: postgis
POSTGRES_DB: flinkjam
volumes:
- "./docker-data/postgis:/var/lib/postgresql/data"
- "./sql/01-enable-hstore.sql:/docker-entrypoint-initdb.d/01-enable-hstore.sql"
ports:
- "5432:5432"
Getting Data into PostGIS
Getting the OSM Data
Thanks to Geofabrik, we can easily download the OSM data. I have decided to use the OSM data for Nordrhein-Westfalen, which is where I am living at:
- https://download.geofabrik.de/europe/germany/
Importing the Data
We can then import the data using osm2pgsql, which is ...
an Open Source tool for importing OpenStreetMap (OSM) data into a PostgreSQL/PostGIS database. Essentially it is a very specialized ETL (Extract-Transform-Load) tool for OpenStreetMap data.
It comes with various pre-built executables at:
From the Command Line I am running the following command to import it into the flinkjam database, which has been defined in the docker-compose.yml file:
osm2pgsql.exe -d flinkjam --hstore -U postgis -W -H localhost -P 5432 -s -C 2000 --flat-nodes=./flat_nodes.cache "C:\Users\philipp\Downloads\nordrhein-westfalen-250618.osm.pbf"
This takes some time to import, here is an example log on my machine:
2025-06-19 16:39:52 osm2pgsql version 2.1.1
2025-06-19 16:39:52 Database version: 16.4 (Debian 16.4-1.pgdg110+2)
2025-06-19 16:39:52 PostGIS version: 3.4
2025-06-19 16:39:52 WARNING: The pgsql (default) output is deprecated. For details see https://osm2pgsql.org/doc/faq.html#the-pgsql-output-is-deprecated-what-does-that-mean
2025-06-19 16:39:52 Initializing properties table '"public"."osm2pgsql_properties"'.
2025-06-19 16:39:52 Storing properties to table '"public"."osm2pgsql_properties"'.
2025-06-19 16:39:52 Setting up table 'planet_osm_point'
2025-06-19 16:39:52 Setting up table 'planet_osm_line'
2025-06-19 16:39:52 Setting up table 'planet_osm_polygon'
2025-06-19 16:39:53 Setting up table 'planet_osm_roads'
2025-06-19 16:51:40 Reading input files done in 707s (11m 47s).
2025-06-19 16:51:40 Processed 83354832 nodes in 42s - 1985k/s
2025-06-19 16:51:40 Processed 13911715 ways in 391s (6m 31s) - 36k/s
2025-06-19 16:51:40 Processed 144827 relations in 274s (4m 34s) - 529/s
2025-06-19 16:51:40 Clustering table 'planet_osm_roads' by geometry...
2025-06-19 16:51:40 Clustering table 'planet_osm_line' by geometry...
2025-06-19 16:51:40 Clustering table 'planet_osm_point' by geometry...
2025-06-19 16:51:40 Clustering table 'planet_osm_polygon' by geometry...
2025-06-19 16:51:42 Building index on middle ways table
2025-06-19 16:51:42 Building indexes on middle rels table
2025-06-19 16:51:42 Done postprocessing on table 'planet_osm_nodes' in 0s
2025-06-19 16:52:03 Creating geometry index on table 'planet_osm_roads'...
2025-06-19 16:52:10 Creating osm_id index on table 'planet_osm_roads'...
2025-06-19 16:52:13 Analyzing table 'planet_osm_roads'...
2025-06-19 16:53:27 Creating geometry index on table 'planet_osm_point'...
2025-06-19 16:54:02 Creating osm_id index on table 'planet_osm_point'...
2025-06-19 16:54:21 Analyzing table 'planet_osm_point'...
2025-06-19 16:55:08 Creating geometry index on table 'planet_osm_line'...
2025-06-19 16:56:01 Creating osm_id index on table 'planet_osm_line'...
2025-06-19 16:56:19 Analyzing table 'planet_osm_line'...
2025-06-19 16:58:47 Creating geometry index on table 'planet_osm_polygon'...
2025-06-19 16:58:55 Done postprocessing on table 'planet_osm_ways' in 391s (6m 31s)
2025-06-19 16:58:55 Done postprocessing on table 'planet_osm_rels' in 22s
2025-06-19 16:58:55 All postprocessing on table 'planet_osm_point' done in 180s (3m 0s).
2025-06-19 16:58:55 All postprocessing on table 'planet_osm_line' done in 290s (4m 50s).
2025-06-19 17:00:14 Creating osm_id index on table 'planet_osm_polygon'...
2025-06-19 17:00:43 Analyzing table 'planet_osm_polygon'...
2025-06-19 17:00:51 All postprocessing on table 'planet_osm_polygon' done in 550s (9m 10s).
2025-06-19 17:00:51 All postprocessing on table 'planet_osm_roads' done in 43s.
2025-06-19 17:00:51 Storing properties to table '"public"."osm2pgsql_properties"'.
2025-06-19 17:00:51 osm2pgsql took 1259s (20m 59s) overall.
Extracting Roads Segments and Traffic Lights
My feeling is, that I need at least road segments and traffic lights to detect congestions.
Preparing the Road Segments Table
So we'll start by creating a table for the road_segments:
DROP TABLE IF EXISTS road_segments;
CREATE TABLE road_segments (
id BIGINT PRIMARY KEY, -- OSM IDs can be very large, so use BIGINT
osm_type VARCHAR(20), -- e.g., 'way' (from osm2pgsql)
type VARCHAR(50), -- e.g., 'Autobahn', 'Bundesstrasse', 'Stadtstrasse' (your classification)
speed_limit_kmh INTEGER, -- Speed limit in km/h
name VARCHAR(255), -- Road name (optional, but useful for debugging)
geom GEOMETRY(LineString, 4326) -- The actual road geometry (WGS84)
);
To speed up queries, we should add a GIST index on the road geometry:
CREATE INDEX idx_road_segments_geom ON road_segments USING GIST(geom);
We can then insert the relevant data of planet_osm_line to the road_segments table:
INSERT INTO road_segments (id, osm_type, type, speed_limit_kmh, name, geom)
SELECT
osm_id AS id,
'way' AS osm_type,
-- Initial classification for 'type' based on common German road types
CASE
WHEN highway = 'motorway' THEN 'Autobahn'
WHEN highway = 'trunk' THEN 'Bundesstrasse'
WHEN highway = 'primary' THEN 'Landesstrasse' -- Often L-roads or major city roads
WHEN highway = 'secondary' THEN 'Landesstrasse' -- Also can be L-roads or significant local roads
WHEN highway = 'tertiary' THEN 'Stadtstrasse' -- Inner city roads
WHEN highway = 'residential' THEN 'Residential'
WHEN highway = 'unclassified' THEN 'Unclassified' -- Roads not clearly classified
WHEN highway = 'service' THEN 'Service Road'
ELSE 'Other Road' -- Catch-all for less relevant types, you might want to filter these out
END AS type,
CASE
WHEN tags -> 'maxspeed' ~ '^[0-9]+$' THEN CAST(tags -> 'maxspeed' AS INTEGER)
WHEN tags -> 'maxspeed' IN ('walk', 'inf') THEN NULL -- Not applicable or unlimited
WHEN tags -> 'maxspeed' = 'DE:urban' THEN 50 -- Default urban speed limit in Germany
WHEN tags -> 'maxspeed' = 'DE:rural' THEN 100 -- Default rural speed limit in Germany
ELSE NULL -- For other unparseable maxspeed values
END AS speed_limit_kmh,
name,
ST_Transform(way, 4326) AS geom -- 'way' is the geometry column from planet_osm_line
FROM
planet_osm_line
WHERE
highway IN ('motorway', 'trunk', 'primary', 'secondary', 'tertiary', 'residential', 'unclassified', 'service')
AND NOT (tunnel = 'yes' AND highway = 'footway') -- Exclude footways in tunnels
AND NOT (bridge = 'yes' AND highway = 'footway'); -- Exclude footways on bridges
While the OSM data has a high quality, it's probably useful to postprocess the data and set the speed limits for road segments, when possible:
UPDATE road_segments
SET speed_limit_kmh = CASE
WHEN type = 'Autobahn' AND speed_limit_kmh IS NULL THEN 130 -- German Autobahn advisory speed (no general limit)
WHEN type IN ('Bundesstrasse', 'Landesstrasse', 'Unclassified') AND speed_limit_kmh IS NULL THEN 100 -- Rural roads
WHEN type IN ('Stadtstrasse', 'Residential', 'Service Road') AND speed_limit_kmh IS NULL THEN 50 -- Urban areas
ELSE speed_limit_kmh -- Keep existing specific speed limits
END
WHERE speed_limit_kmh IS NULL; -- Only update rows where speed_limit_kmh is currently NULL
I am unsure, wether planet_osm_roads would be better suited? We will see.
Preparing the Traffic Lights Table
For Traffic Light information, we'll start by
CREATE TABLE traffic_lights (
id BIGINT PRIMARY KEY, -- OSM ID of the traffic light node
name VARCHAR(255), -- Optional: Name of the intersection or road
geom GEOMETRY(Point, 4326), -- The geographical point of the traffic light
is_pedestrian_crossing_light BOOLEAN DEFAULT FALSE -- To distinguish car signals from pedestrian signals
);
And create a GiST index for faster lookups:
CREATE INDEX idx_traffic_lights_geom ON traffic_lights USING GIST(geom);
We will then insert all traffic lights we'll find in the OSM data:
INSERT INTO traffic_lights (id, name, geom, is_pedestrian_crossing_light)
SELECT
osm_id AS id,
name,
ST_Transform(way, 4326) AS geom, -- 'way' is the geometry column for points in planet_osm_point
CASE
WHEN tags -> 'crossing' = 'traffic_signals' THEN TRUE -- Use tags->'crossing' for hstore
ELSE FALSE
END AS is_pedestrian_crossing_light
FROM
planet_osm_point
WHERE
-- Select main traffic signals for vehicles (check highway tag directly)
highway = 'traffic_signals'
OR
-- Select traffic signals specifically for crossings (check tags hstore for crossing=traffic_signals)
(tags ? 'crossing' AND tags -> 'crossing' = 'traffic_signals');
And finally we are deleting duplicates found in the OSM data:
DELETE FROM traffic_lights
WHERE ctid IN (
SELECT ctid
FROM (
SELECT
ctid,
ROW_NUMBER() OVER (PARTITION BY id ORDER BY ctid) as rn
FROM traffic_lights
) AS duplicates
WHERE duplicates.rn > 1 -- Select all rows except the first one in each partition (i.e., the duplicates)
);
Trying it out
So now let's get a coordinate to check a position, which I have stood in traffic jams hours of my life:
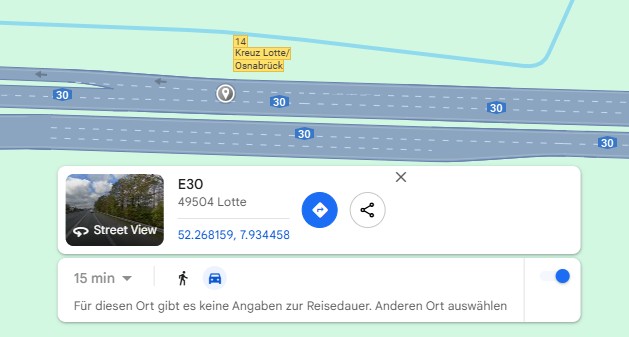
So the Position is Latitude = 52.268159, Longitude = 7.934458.
I've checked the raw OSM data, that we are looking for the osm_id 315039636 (trust me 🤭).
If we now put together a query:
SELECT
id,
osm_type,
type,
speed_limit_kmh,
name,
geom <-> ST_SetSRID(ST_MakePoint(7.934472, 52.268167), 4326)::geography as distance
FROM
road_segments
WHERE
ST_DWithin(geom, ST_SetSRID(ST_MakePoint(7.934472, 52.268167), 4326)::geography, 5)
ORDER BY
distance asc
We get the correct results back:
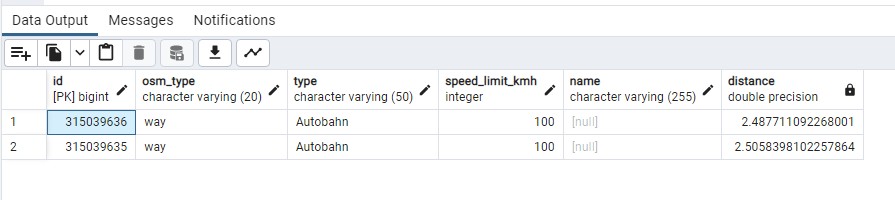
But the query is super slow 😞:
Successfully run. Total query runtime: 2 secs 929 msec.
2 rows affected.
With almost three seconds on the clock, we should probably stop this altogether?
But let's not give up so quickly and see what the query Planner tells us, when we are running
an EXPLAIN ANALYZE:
EXPLAIN ANALYZE
SELECT
id,
osm_type,
type,
speed_limit_kmh,
name,
geom <-> ST_SetSRID(ST_MakePoint(7.934472, 52.268167), 4326)::geography as distance
FROM
road_segments
WHERE
ST_DWithin(geom, ST_SetSRID(ST_MakePoint(7.934472, 52.268167), 4326)::geography, 5)
ORDER BY
distance asc
It shows, that despite having a GiST index on the geom column, it isn't hit and thus the
query will do a Full Table scan and not make any use of an index:
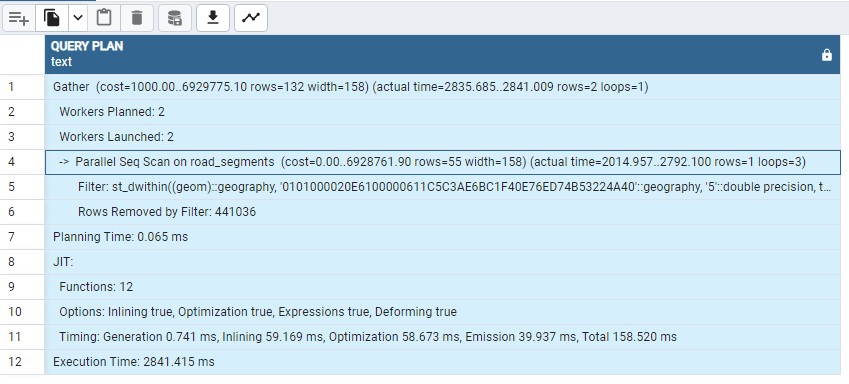
Why is that? 🤔
My feeling? I am no Postgres expert, but I am pretty confident it has to do with the ST_DWITHIN and its data types.
Although the method signature tells us you could pass it geometry and geography data types, I suspect we need another index:
Synopsis
boolean ST_DWithin(geometry g1, geometry g2, double precision distance_of_srid);
boolean ST_DWithin(geography gg1, geography gg2, double precision distance_meters, boolean use_spheroid = true);
So I am adding another GiST index on the geom column, but this time I am indexing it as a geography:
CREATE INDEX road_segments_geom_geography ON road_segments USING gist( (geom::geography) );
And in the EXPLAIN ANALYZE results, we can now see the index condition being hit:
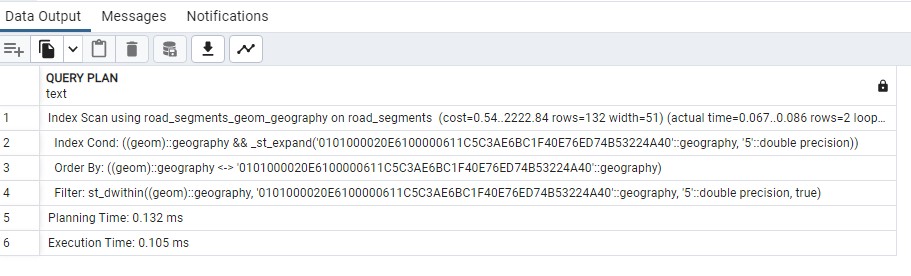
And the query now completes 60 times faster or so, in:
00:00:00.056 seconds
Conclusion
We have spun up a Postgis instance, downloaded & imported the OSM data using osm2pgsql.
We have then pre-processed the road and traffic light data into two tables, that allows us to better index the data and improve query speed.
The initial queries had been very slow, but by using an additional index, we have seen a huge performance boost.