I have recently grown very tired of the GitHub Code Search, because it doesn't provide a way to sort search results by last commited date. The search now basically yields outdated results and obsolete code. And it's unlikely to see sorting any time soon, due to the way GitHub currently builds its index.
But what if we could develop our own Code Search and base it on Elasticsearch? Elasticsearch has been used by GitHub for years and it is still used by GitLab. What's good enough for them might be good enough for us, right?
In this part of the series we will implement a ASP.NET Core Backend, which uses Elasticsearch as its search engine. We will see how GitLab uses Elasticsearch to provide a Search index and see how to recreate it in ASP.NET Core.
All code in this article can be found at:
Table of contents
What we are going to build
The final result is a Search Engine, that allows us to search for code and sort the results by name, date and other fields. The idea is to index all repositories of an owner, such as Microsoft, and search code through their repositories.
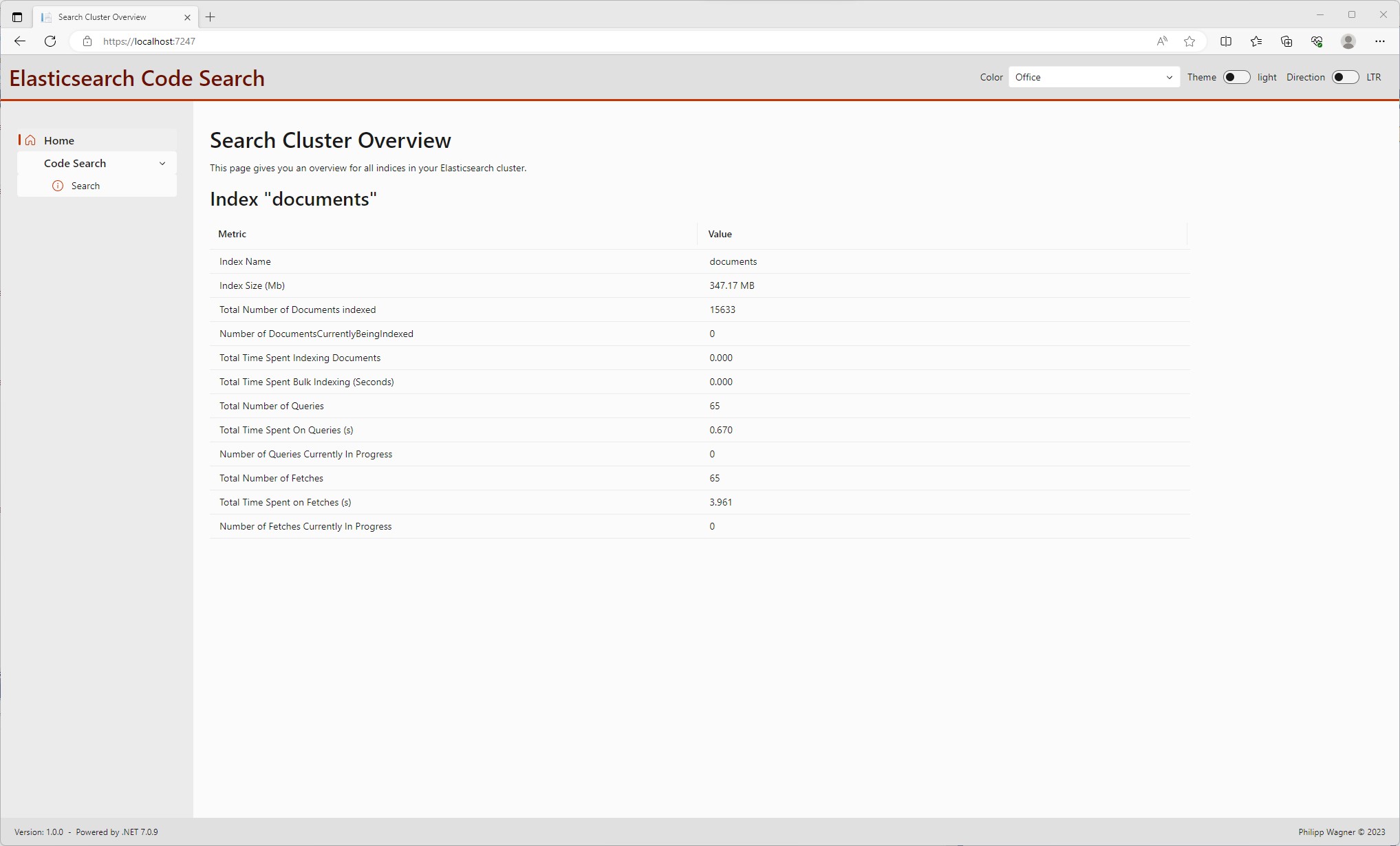
There is an overview, which shows the Cluster Health ...
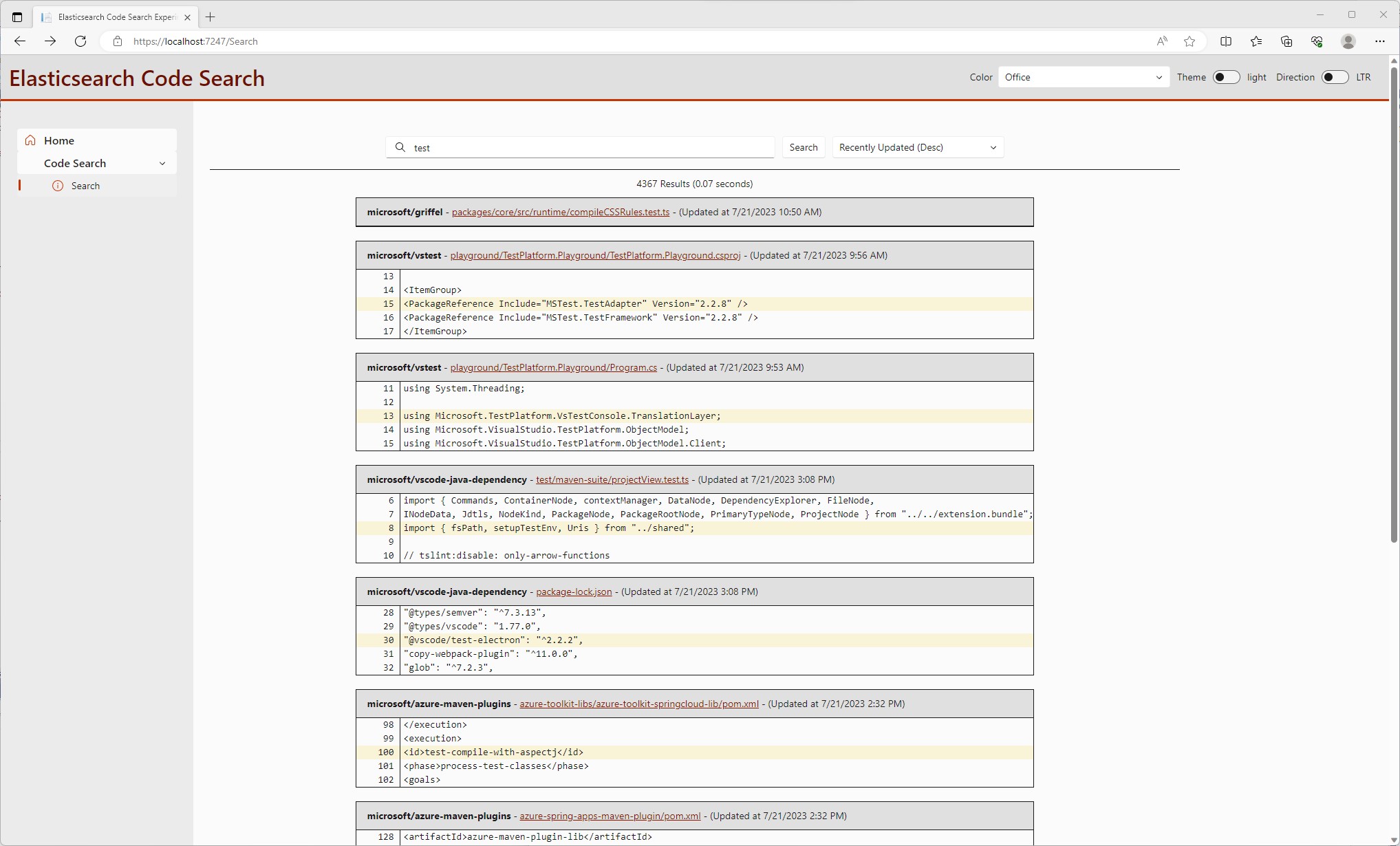
And a Search page to query the Elasticsearch Cluster ...
Researching Elasticsearch
Code Search Index and Mappings
GitLab uses Elasticsearch. GitLab is opensource. There's a lot to learn it it and I think it's a good idea
to dive straight into the Elasticsearch Config file of GitLab. It's located in the file config.rb.
The configuration starts by defining the Elasticsearch analyzers, filters, tokenizers and normalizers used when indexing code:
module Elastic
module Latest
module Config
# ...
settings \
analysis: {
analyzer: {
default: {
tokenizer: 'standard',
filter: %w(lowercase stemmer)
},
my_ngram_analyzer: {
tokenizer: 'my_ngram_tokenizer',
filter: ['lowercase']
},
path_analyzer: {
type: 'custom',
tokenizer: 'path_tokenizer',
filter: %w(lowercase asciifolding)
},
code_analyzer: {
type: 'custom',
tokenizer: 'whitespace',
filter: %w(word_delimiter_graph_filter flatten_graph lowercase asciifolding remove_duplicates)
},
whitespace_reverse: {
tokenizer: 'whitespace',
filter: %w(lowercase asciifolding reverse)
},
email_analyzer: {
tokenizer: 'email_tokenizer'
}
},
filter: {
word_delimiter_graph_filter: {
type: 'word_delimiter_graph',
preserve_original: true
}
},
tokenizer: {
my_ngram_tokenizer: {
type: 'ngram',
min_gram: 2,
max_gram: 3,
token_chars: %w(letter digit)
},
path_tokenizer: {
type: 'path_hierarchy',
reverse: true
},
email_tokenizer: {
type: 'uax_url_email'
}
},
normalizer: {
sha_normalizer: {
type: "custom",
filter: ["lowercase"]
}
}
}
# ...
end
end
end
The Config then defines a set of indexes, but we are only interested in the index for the "blob" content. This
basically is the Code Document, that we are going to index.
module Elastic
module Latest
module Config
# ...
# Since we can't have multiple types in ES6, but want to be able to use JOINs, we must declare all our
# fields together instead of per model
mappings dynamic: 'strict' do
# ...
### REPOSITORIES
indexes :blob do
indexes :type, type: :keyword
indexes :id, type: :keyword, index_options: 'docs', normalizer: :sha_normalizer
indexes :rid, type: :keyword
indexes :oid, type: :keyword, index_options: 'docs', normalizer: :sha_normalizer
indexes :commit_sha, type: :keyword, index_options: 'docs', normalizer: :sha_normalizer
indexes :path, type: :text, analyzer: :path_analyzer
indexes :file_name,
type: :text, analyzer: :code_analyzer,
fields: { reverse: { type: :text, analyzer: :whitespace_reverse } }
indexes :content,
type: :text, index_options: 'positions', analyzer: :code_analyzer
indexes :language, type: :keyword
end
end
end
end
Elasticsearch Code Highlighting
Elasticsearch allows to pass a so called highlighter to a query, that allows us to highlight a match. GitLab doesn't highlight the exact match, but the entire line. I think, that's cool and I want to understand how it's done.
There are two constants defined in git_class_proxy.rb:
module Elastic
module Latest
module GitClassProxy
# ...
HIGHLIGHT_START_TAG = 'gitlabelasticsearch→'
HIGHLIGHT_END_TAG = '←gitlabelasticsearch'
# ...
These constants are used for an Elasticsearch highlighter as pre_tags and post_tags. To
get the entire content of the file, the number of fragments is set to 0. By doing so we can
later determine, how many lines have been matched and so on.
module Elastic
module Latest
module GitClassProxy
def blob_query(query, type: 'blob', page: 1, per: 20, options: {})
# ...
if options[:highlight] && !count_or_aggregation_query
# Highlighted text fragments do not work well for code as we want to show a few whole lines of code.
# Set number_of_fragments to 0 to get the whole content to determine the exact line number that was
# highlighted.
query_hash[:highlight] = {
pre_tags: [HIGHLIGHT_START_TAG],
post_tags: [HIGHLIGHT_END_TAG],
number_of_fragments: 0,
fields: {
"blob.content" => {},
"blob.file_name" => {}
}
}
end
end
# ...
end
end
In the search_results.rb we can see how GitLab uses the highlighted content. It is first
scanned for the HIGHLIGHT_START_TAG constant and checks how many lines matched, then it
determines the start index and takes the 2 preceeding and 2 succeeding lines if possible:
highlight_content = get_highlight_content(result)
found_line_number = 0
highlight_found = false
matched_lines_count = highlight_content.scan(/#{::Elastic::Latest::GitClassProxy::HIGHLIGHT_START_TAG}(.*?)\R/o).size
highlight_content.each_line.each_with_index do |line, index|
next unless line.include?(::Elastic::Latest::GitClassProxy::HIGHLIGHT_START_TAG)
found_line_number = index
highlight_found = true
break
end
from = if found_line_number >= 2
found_line_number - 2
else
found_line_number
end
to = if (total_lines - found_line_number) > 3
found_line_number + 2
else
found_line_number
end
data = content.lines[from..to]
# only send highlighted line number if a highlight was returned by Elasticsearch
highlight_line = highlight_found ? found_line_number + 1 : nil
And that's it for Elasticsearch in GitLab. There's of course some pieces missing, but they are not relevant here.
All we need to do is to basically translate all this to C# and use the Elasticsearch .NET Client.
Elasticsearch Code Search with .NET
We now have a basic understanding of using Elasticsearch for code search. All that's left to do is to translate it to .NET!
Elasticsearch Settings using the Options Pattern
We need a Uri for the target Elasticsearch instance, an Elasticsearch username, password and certificate fingerprint to connect to a node. You can learn about it here:
The Options pattern in ASP.NET Core is a good way to have these settings configurable. In production systems you should think about using an Azure Vault (or something similar) to set these sensitive credentials.
So we start by defining the ElasticCodeSearchOptions:
// Licensed under the MIT license. See LICENSE file in the project root for full license information.
namespace ElasticsearchCodeSearch.Options
{
/// <summary>
/// Elasticsearch options.
/// </summary>
public class ElasticCodeSearchOptions
{
/// <summary>
/// Endpoint of the Elasticsearch Node.
/// </summary>
public required string Uri { get; set; }
/// <summary>
/// Index to use for Code Search.
/// </summary>
public required string IndexName { get; set; }
/// <summary>
/// Elasticsearch Username.
/// </summary>
public required string Username { get; set; }
/// <summary>
/// Elasticsearch Password.
/// </summary>
public required string Password { get; set; }
/// <summary>
/// Certificate Fingerprint for trusting the Certificate.
/// </summary>
public required string CertificateFingerprint { get; set; }
}
}
In the Program.cs we register the options as:
// Add Options
builder.Services.AddOptions();
builder.Services.Configure<ElasticCodeSearchOptions>(builder.Configuration.GetSection("Elasticsearch"));
And in the appsettings.json we add our settings for the local Elasticsearch instance.
{
"Elasticsearch": {
"Uri": "https://localhost:9200",
"IndexName": "documents",
"Username": "elastic",
"Password": "8ASnZftGbgJH5QzwobIv",
"CertificateFingerprint": "a6390608f670486f1bc31fe6e8d78fdb93f6026bd9ce58f0732961d362fd9f82"
}
}
Code Search Domain Model
The code to be indexed will be put into a codeSearchDocument, which holds all data to be indexed:
// Licensed under the MIT license. See LICENSE file in the project root for full license information.
namespace ElasticsearchCodeSearch.Models
{
/// <summary>
/// A code document, which should be indexed and searchable by Elasticsearch.
/// </summary>
public class CodeSearchDocument
{
/// <summary>
/// Gets or sets the Id.
/// </summary>
public required string Id { get; set; }
/// <summary>
/// Gets or sets the owner (organization or user).
/// </summary>
public required string Owner { get; set; }
/// <summary>
/// Gets or sets the repository.
/// </summary>
public required string Repository { get; set; }
/// <summary>
/// Gets or sets the filepath.
public required string Path { get; set; }
/// <summary>
/// Gets or sets the filename.
public required string Filename { get; set; }
/// <summary>
/// Gets or sets the commit hash.
public required string CommitHash { get; set; }
/// <summary>
/// Gets or sets the content to index.
/// </summary>
public required string Content { get; set; } = string.Empty;
/// <summary>
/// Gets or sets the Permalink to the file.
/// </summary>
public string Permalink { get; set; } = string.Empty;
/// <summary>
/// Gets or sets the latest commit date.
/// </summary>
public required DateTimeOffset LatestCommitDate { get; set; }
}
}
The search query is a CodeSearchRequest, which also holds the information about pagination and sorting
the results. All fields are required, so you always need to pass pagination information and a sorting.
// Licensed under the MIT license. See LICENSE file in the project root for full license information.
namespace ElasticsearchCodeSearch.Models
{
/// <summary>
/// A Search Request, which will be converted to Elasticsearch.
/// </summary>
public class CodeSearchRequest
{
/// <summary>
/// Gets or sets the Search Query.
/// </summary>
public required string Query { get; set; }
/// <summary>
/// Gets or sets the number of documents to skip.
/// </summary>
public required int From { get; set; } = 0;
/// <summary>
/// Gets or sets the number of documents to fetch.
/// </summary>
public required int Size { get; set; } = 10;
/// <summary>
/// Gets or sets the sort fields.
/// </summary>
public required List<SortField> Sort { get; set; } = new List<SortField>();
}
}
A SortField contains a field name and a sort order.
// Licensed under the MIT license. See LICENSE file in the project root for full license information.
namespace ElasticsearchCodeSearch.Models
{
/// <summary>
/// Sort Field.
/// </summary>
public class SortField
{
/// <summary>
/// Gets or sets the Sort Field.
/// </summary>
public required string Field { get; set; }
/// <summary>
/// Gets or sets the Sort Order.
/// </summary>
public required SortOrderEnum Order { get; set; } = SortOrderEnum.Ascending;
}
}
And the sort order can either be ascending or descending, which is given in a SortOrderEnum:
// Licensed under the MIT license. See LICENSE file in the project root for full license information.
namespace ElasticsearchCodeSearch.Models
{
/// <summary>
/// Sort Order.
/// </summary>
public enum SortOrderEnum
{
/// <summary>
/// Ascending.
/// </summary>
Ascending = 1,
/// <summary>
/// Descending.
/// </summary>
Descending = 2
}
}
And all this for what? Exactely, for displaying some highlighted content, which is given in
HighlightedContent (not the best name though, but I couldn't up with a better name).
// Licensed under the MIT license. See LICENSE file in the project root for full license information.
namespace ElasticsearchCodeSearch.Models
{
/// <summary>
/// Holds the line number and line content for a match, and it
/// has the information if the content needs highlighting.
/// </summary>
public class HighlightedContent
{
/// <summary>
/// Gets or sets the line number.
/// </summary>
public int LineNo { get; set; }
/// <summary>
/// Gets or sets the line content.
/// </summary>
public string Content { get; set; } = string.Empty;
/// <summary>
/// Gets or sets the flag, if this line needs to be highlighted.
/// </summary>
public bool IsHighlight { get; set; }
}
}
Elasticsearch Code Search Client
We then add the Elasticsearch .NET Client to our Project by running:
dotnet add package Elastic.Clients.Elasticsearch
You can find a pretty good tutorial for getting started with the Elasticsearch .NET Client here:
The Options are going to be injected to a ElasticCodeSearchClient, which takes care of connecting
to Elasticsearch. It will create the index, send queries and bulk index requests. So first of all
we inject the options as a IOptions<ElasticCodeSearchOptions>.
// Licensed under the MIT license. See LICENSE file in the project root for full license information.
// ...
namespace ElasticsearchCodeSearch.Elasticsearch
{
public class ElasticCodeSearchClient
{
private readonly ILogger<ElasticCodeSearchClient> _logger;
private readonly ElasticsearchClient _client;
private readonly string _indexName;
public ElasticCodeSearchClient(ILogger<ElasticCodeSearchClient> logger, IOptions<ElasticCodeSearchOptions> options)
{
_logger = logger;
_indexName = options.Value.IndexName;
_client = CreateClient(options.Value);
}
public virtual ElasticsearchClient CreateClient(ElasticCodeSearchOptions options)
{
var settings = new ElasticsearchClientSettings(new Uri(options.Uri))
.CertificateFingerprint(options.CertificateFingerprint)
.Authentication(new BasicAuthentication(options.Username, options.Password));
return new ElasticsearchClient(settings);
}
}
}
To recreate the config.rb of GitLab, where the index for the code has been defined, we can use the Fluent API of the Elasticsearch .NET client. We recreate the Normalizers, Analyzers, Tokenizers and finally create the index with a mapping similar to GitLab.
// Licensed under the MIT license. See LICENSE file in the project root for full license information.
// ...
namespace ElasticsearchCodeSearch.Elasticsearch
{
public class ElasticCodeSearchClient
{
// ...
public async Task<CreateIndexResponse> CreateIndexAsync(CancellationToken cancellationToken)
{
_logger.TraceMethodEntry();
var createIndexResponse = await _client.Indices.CreateAsync(_indexName, descriptor => descriptor
.Settings(settings => settings
.Analysis(analysis => analysis
.Normalizers(normalizers => normalizers
.Custom("sha_normalizer", normalizer => normalizer
.Filter(new[] { "lowercase" })
)
)
.Analyzers(analyzers => analyzers
.Custom("default", custom => custom
.Tokenizer("standard").Filter(new[]
{
"lowercase",
"stemmer"
})
)
.Custom("whitespace_reverse", custom => custom
.Tokenizer("whitespace").Filter(new[]
{
"lowercase",
"asciifolding",
"reverse"
})
)
.Custom("code_analyzer", custom => custom
.Tokenizer("whitespace").Filter(new[]
{
"word_delimiter_graph_filter",
"flatten_graph",
"lowercase",
"asciifolding",
"remove_duplicates"
})
)
.Custom("custom_path_tree", custom => custom
.Tokenizer("custom_hierarchy")
)
.Custom("custom_path_tree_reversed", custom => custom
.Tokenizer("custom_hierarchy_reversed")
)
)
.Tokenizers(tokenizers => tokenizers
.PathHierarchy("custom_hierarchy", tokenizer => tokenizer
.Delimiter("/"))
.PathHierarchy("custom_hierarchy_reversed", tokenizer => tokenizer
.Reverse(true).Delimiter("/"))
)
.TokenFilters(filters => filters
.WordDelimiterGraph("word_delimiter_graph_filter", filter => filter
.PreserveOriginal(true)
)
)
)
)
.Mappings(mapping => mapping
.Properties<CodeSearchDocument>(properties => properties
.Keyword(properties => properties.Id, keyword => keyword
.IndexOptions(IndexOptions.Docs)
.Normalizer("sha_normalizer")
)
.Keyword(properties => properties.Owner)
.Keyword(properties => properties.Repository)
.Text(properties => properties.Path, text => text
.Fields(fields => fields
.Text("tree", tree => tree.Analyzer("custom_path_tree"))
.Text("tree_reversed", tree_reversed => tree_reversed.Analyzer("custom_path_tree_reversed"))
)
)
.Text(properties => properties.Filename, text => text
.Analyzer("code_analyzer")
.Store(true)
.Fields(fields => fields
.Text("reverse", tree => tree.Analyzer("whitespace_reverse"))
)
)
.Keyword(properties => properties.CommitHash, keyword => keyword
.IndexOptions(IndexOptions.Docs)
.Normalizer("sha_normalizer")
)
.Text(properties => properties.Content, text => text
.IndexOptions(IndexOptions.Positions)
.Analyzer("code_analyzer")
.TermVector(TermVectorOption.WithPositionsOffsetsPayloads)
.Store(true))
.Keyword(properties => properties.Permalink)
.Date(properties => properties.LatestCommitDate))), cancellationToken);
if (_logger.IsDebugEnabled())
{
_logger.LogDebug("CreateIndexResponse DebugInformation: {DebugInformation}", createIndexResponse.DebugInformation);
}
return createIndexResponse;
}
// ...
}
}
An Indexer is going to send a batch of CodeSearchDocument to the service, which will be indexed using the
Elasticsearch Bulk API. So we add a method ElasticCodeSearchClient#BulkIndexAsync.
// Licensed under the MIT license. See LICENSE file in the project root for full license information.
// ...
namespace ElasticsearchCodeSearch.Elasticsearch
{
public class ElasticCodeSearchClient
{
// ...
public async Task<BulkResponse> BulkIndexAsync(IEnumerable<CodeSearchDocument> documents, CancellationToken cancellationToken)
{
_logger.TraceMethodEntry();
var bulkResponse = await _client.BulkAsync(b => b
.Index(_indexName)
.IndexMany(documents), cancellationToken);
if (_logger.IsDebugEnabled())
{
_logger.LogDebug("BulkResponse DebugInformation: {DebugInformation}", bulkResponse.DebugInformation);
}
return bulkResponse;
}
// ...
}
}
And finally we can get to the query. We have seen, that GitLab defines a HIGHLIGHT_START_TAG and HIGHLIGHT_END_TAG as
constants. So we need to define them as well and do so in a static class ElasticsearchConstants.
// Licensed under the MIT license. See LICENSE file in the project root for full license information.
namespace ElasticsearchCodeSearch.Elasticsearch
{
/// <summary>
/// Constants used by the Frontend and Backend.
/// </summary>
public static class ElasticsearchConstants
{
/// <summary>
/// A tag used to find the highlightning start position.
/// </summary>
public static readonly string HighlightStartTag = "elasticsearchcodesearch→";
/// <summary>
/// A tag used to find the highlightning end position.
/// </summary>
public static readonly string HighlightEndTag = "←elasticsearchcodesearch";
}
}
Then we add a Method ElasticCodeSearchClient#SearchAsync to translate the CodeSearchRequest to Elasticsearch using the Elasticsearch .NET Client
API. It uses the previously defined constants as pre tags and post tags for highlighting.
namespace ElasticsearchCodeSearch.Elasticsearch
{
public class ElasticCodeSearchClient
{
// ...
public Task<SearchResponse<CodeSearchDocument>> SearchAsync(CodeSearchRequest searchRequest, CancellationToken cancellationToken)
{
_logger.TraceMethodEntry();
// Convert to Elasticsearch Sort Fields
var sortOptionsArray = searchRequest.Sort
.Select(sortField => ConvertToSortOptions(sortField))
.ToArray();
// Build the Search Query:
return _client.SearchAsync<CodeSearchDocument>(searchRequestDescriptor => searchRequestDescriptor
// Query this Index:
.Index(_indexName)
// Setup Pagination:
.From(searchRequest.From).Size(searchRequest.Size)
// Setup the QueryString:
.Query(q => q
.QueryString(new QueryStringQuery()
{
AllowLeadingWildcard = true,
Query = searchRequest.Query,
})
)
// Setup the Highlighters:
.Highlight(highlight => highlight
.Fields(fields => fields
.Add(Infer.Field<CodeSearchDocument>(f => f.Content), new HighlightField
{
Fragmenter = HighlighterFragmenter.Span,
PreTags = new[] { ElasticsearchConstants.HighlightStartTag },
PostTags = new[] { ElasticsearchConstants.HighlightEndTag },
NumberOfFragments = 0,
})
.Add(Infer.Field<CodeSearchDocument>(f => f.Filename), new HighlightField
{
Fragmenter = HighlighterFragmenter.Span,
PreTags = new[] { ElasticsearchConstants.HighlightStartTag },
PostTags = new[] { ElasticsearchConstants.HighlightEndTag },
NumberOfFragments = 0,
})
)
)
// Setup the Search Order:
.Sort(sortOptionsArray), cancellationToken);
}
private static SortOptions ConvertToSortOptions(SortField sortField)
{
var sortOrder = sortField.Order == SortOrderEnum.Ascending ? SortOrder.Asc : SortOrder.Desc;
return SortOptions.Field(new Field(sortField.Field), new FieldSort { Order = sortOrder });
}
}
}
Finally make sure to register the ElasticCodeSearchClient. We can make it a Singleton:
// Add Client
builder.Services.AddSingleton<ElasticCodeSearchClient>();
ASP.NET Core Web API Endpoints for Code Search
The simplest way to expose the Code Search is to use a ASP.NET Core Web API, define some Data Transfer Objects and use Swagger for providing an OpenAPI Schema (and testing).
I came up with three endpoints for indexing, searching and deleting code:
| Endpoint | Description |
| ------------------------------- | ------------------------------------------------------------------------ |
| `POST /search-documents` | Searches for code and returns the matching documents and code snippets |
| `POST /index-documents` | Bulk Indexes the code search documents |
| `POST /delete-all-documents` | Delete all documents in the index. Useful for testing. |
Data Transfer Objects
The idea is to create a shared project and share the DTOs between the Backend and the Frontend. It's going to be Blazor, so we should take advantadge of and share code.
We start by modelling the most important piece, the CodeSearchDocumentDto. It is used to transfer
the code document and its metadata to the Backend.
/// <summary>
/// A code document, which should be indexed and searchable by Elasticsearch.
/// </summary>
public class CodeSearchDocumentDto
{
/// <summary>
/// Gets or sets the Id.
/// </summary>
[Required]
[JsonPropertyName("id")]
public required string Id { get; set; }
/// <summary>
/// Gets or sets the owner (user or organization).
/// </summary>
[Required]
[JsonPropertyName("owner")]
public required string Owner { get; set; }
/// <summary>
/// Gets or sets the Repository Name.
/// </summary>
[Required]
[JsonPropertyName("repository")]
public required string Repository { get; set; }
/// <summary>
/// Gets or sets the filename.
/// </summary>
[Required]
[JsonPropertyName("filename")]
public required string Filename { get; set; }
/// <summary>
/// Gets or sets the relative file path.
/// </summary>
[Required]
[JsonPropertyName("path")]
public required string Path { get; set; }
/// <summary>
/// Gets or sets the commit hash.
/// </summary>
[Required]
[JsonPropertyName("commitHash")]
public required string CommitHash { get; set; }
/// <summary>
/// Gets or sets the content to index.
/// </summary>
[JsonPropertyName("content")]
public string? Content { get; set; } = string.Empty;
/// <summary>
/// Gets or sets the Permalink to the file.
/// </summary>
[Required]
[JsonPropertyName("permalink")]
public required string Permalink { get; set; }
/// <summary>
/// Gets or sets the latest commit date.
/// </summary>
[Required]
[JsonPropertyName("latestCommitDate")]
public required DateTimeOffset LatestCommitDate { get; set; }
}
For code search requests, we want to sort the data for example by repository, owner
or latest commit date. We start by defining a SortOrderEnumDto.
/// <summary>
/// Sort Order.
/// </summary>
public enum SortOrderEnumDto
{
/// <summary>
/// Ascending.
/// </summary>
Asc = 1,
/// <summary>
/// Descending.
/// </summary>
Desc = 2
}
And we need the Field name, so we also define a SortFieldDto.
/// <summary>
/// Sort Field.
/// </summary>
public class SortFieldDto
{
/// <summary>
/// Gets or sets the field name to sort.
/// </summary>
[Required]
[JsonPropertyName("field")]
public required string Field { get; set; }
/// <summary>
/// Gets or sets the sort order.
/// </summary>
[Required]
[JsonPropertyName("order")]
[JsonConverter(typeof(JsonStringEnumConverter))]
public SortOrderEnumDto Order { get; set; } = SortOrderEnumDto.Asc;
}
All this goes into a search request, that we call a CodeSearchRequestDto. It should support
paginating the results, so we don't transmit too much data. The Query String is the Elasticsearch
Query String format, so we do not reinvent the wheel.
/// <summary>
/// The Client sends a <see cref="CodeSearchDocumentDto"/> to filter for
/// documents, paginate and sort the results. The Search Query is given as
/// a Query String.
/// </summary>
public class CodeSearchRequestDto
{
/// <summary>
/// Gets or sets the Query String.
/// </summary>
[Required]
[JsonPropertyName("query")]
public required string Query { get; set; }
/// <summary>
/// Gets or sets the number of hits to skip, defaulting to 0.
/// </summary>
[Required]
[JsonPropertyName("from")]
public int From { get; set; } = 0;
/// <summary>
/// Gets or sets the number of hits to return, defaulting to 10.
/// </summary>
[Required]
[JsonPropertyName("size")]
public int Size { get; set; } = 10;
/// <summary>
/// Gets or sets the sort fields for the results.
/// </summary>
[Required]
[JsonPropertyName("sort")]
public List<SortFieldDto> Sort { get; set; } = new List<SortFieldDto>();
}
The Search Results are called a CodeSearchResultsDto, which contains the information
about the request, the total number of matched documents and a list of the matching
documents in the CodeSearchResultDto.
/// <summary>
/// Holds the Paginated Code Search Results.
/// </summary>
public class CodeSearchResultsDto
{
/// <summary>
/// Gets or sets the query string, that has been used.
/// </summary>
[Required]
[JsonPropertyName("query")]
public required string Query { get; set; }
/// <summary>
/// Gets or sets the number of hits to skip, defaulting to 0.
/// </summary>
[Required]
[JsonPropertyName("from")]
public required int From { get; set; }
/// <summary>
/// Gets or sets the number of hits to return, defaulting to 10.
/// </summary>
[Required]
[JsonPropertyName("size")]
public required int Size { get; set; }
/// <summary>
/// Gets or sets the total Number of matched documents.
/// </summary>
[Required]
[JsonPropertyName("total")]
public required int Total { get; set; }
/// <summary>
/// Gets or sets the sort fields used.
/// </summary>
[Required]
[JsonPropertyName("sort")]
public required List<SortFieldDto> Sort { get; set; } = new List<SortFieldDto>();
/// <summary>
/// Gets or sets the search results.
/// </summary>
[Required]
[JsonPropertyName("results")]
public required List<CodeSearchResultDto> Results { get; set; }
}
A Search Result is called a CodeSearchResultDto and needs to transmit the matched document's
metadata and 5 highlighted lines. We will not transfer the entire content, because the Frontend
doesn't need it, it is better to query those when demanded.
/// <summary>
/// Holds the Search Results along with the highlighted matches.
/// </summary>
public class CodeSearchResultDto
{
/// <summary>
/// Gets or sets the Id.
/// </summary>
[JsonPropertyName("Id")]
public required string Id { get; set; }
/// <summary>
/// Gets or sets the owner.
/// </summary>
[JsonPropertyName("owner")]
public required string Owner { get; set; }
/// <summary>
/// Gets or sets the repository name.
/// </summary>
[JsonPropertyName("repository")]
public required string Repository { get; set; }
/// <summary>
/// Gets or sets the relative file path.
/// </summary>
[JsonPropertyName("path")]
public required string Path { get; set; }
/// <summary>
/// Gets or sets the filename.
/// </summary>
[JsonPropertyName("filename")]
public required string Filename { get; set; }
/// <summary>
/// Gets or sets the Permalink.
/// </summary>
[JsonPropertyName("permalink")]
public required string Permalink { get; set; }
/// <summary>
/// Gets or sets the Highlighted Content, which is the lines.
/// </summary>
[JsonPropertyName("content")]
public required List<HighlightedContentDto> Content { get; set; }
/// <summary>
/// Gets or sets the latest commit date.
/// </summary>
[JsonPropertyName("latestCommitDate")]
public required DateTimeOffset LatestCommitDate { get; set; }
}
The Highlighted Content is given in the HighlightedContentDto, which contains a single line. It
is going to be displayed in the Search Result Code Box, so we need the line number of the match,
the content of the line and the information, if it needs to be highlighted or not.
/// <summary>
/// Highlighted Line of Code.
/// </summary>
public class HighlightedContentDto
{
/// <summary>
/// Gets or sets the line number.
/// </summary>
public int LineNo { get; set; }
/// <summary>
/// Gets or sets the line content.
/// </summary>
public string Content { get; set; } = string.Empty;
/// <summary>
/// Gets or sets the information, if the content needs to be highlighted.
/// </summary>
public bool IsHighlight { get; set; }
}
Adding a ASP.NET Core Web API Controller
At this point we can implement the CodeSearchController with the three endpoints. You can see
how it injects the ElasticCodeSearchClient and uses several converter classes to convert between
the Data Transfer Objects and the Domain Model.
// Licensed under the MIT license. See LICENSE file in the project root for full license information.
// ...
namespace ElasticsearchCodeSearch.Controllers
{
[ApiController]
public class CodeSearchController : ControllerBase
{
private readonly ILogger<CodeSearchController> _logger;
private readonly ElasticCodeSearchClient _elasticsearchClient;
public CodeSearchController(ILogger<CodeSearchController> logger, ElasticCodeSearchClient elasticsearchClient)
{
_elasticsearchClient = elasticsearchClient;
_logger = logger;
}
[HttpPost]
[Route("/delete-all-documents")]
public async Task<IActionResult> DeleteAllDocuments(CancellationToken cancellationToken)
{
_logger.TraceMethodEntry();
try
{
var deleteAllResponse = await _elasticsearchClient.DeleteAllAsync(cancellationToken);
if (!deleteAllResponse.IsValidResponse)
{
if (_logger.IsErrorEnabled())
{
deleteAllResponse.TryGetOriginalException(out var originalException);
_logger.LogError(originalException, "Elasticsearch failed with an unhandeled Exception");
}
return BadRequest("Invalid Search Response from Elasticsearch");
}
return Ok();
}
catch (Exception e)
{
if (_logger.IsErrorEnabled())
{
_logger.LogError(e, "An unhandeled exception occured");
}
return StatusCode(500, "An internal Server Error occured");
}
}
[HttpPost]
[Route("/search-documents")]
public async Task<IActionResult> SearchDocuments([FromBody] CodeSearchRequestDto request, CancellationToken cancellationToken)
{
_logger.TraceMethodEntry();
try
{
var searchRequest = CodeSearchRequestConverter.Convert(request);
var searchResponse = await _elasticsearchClient.SearchAsync(searchRequest, cancellationToken);
if (!searchResponse.IsValidResponse)
{
if (_logger.IsErrorEnabled())
{
searchResponse.TryGetOriginalException(out var originalException);
_logger.LogError(originalException, "Elasticsearch failed with an unhandeled Exception");
}
return BadRequest("Invalid Search Response from Elasticsearch");
}
var codeSearchResults = new CodeSearchResultsDto
{
Query = request.Query,
From = request.From,
Size = request.Size,
Sort = request.Sort,
Total = (int) searchResponse.Total,
Results = CodeSearchResultConverter.Convert(searchResponse)
};
return Ok(codeSearchResults);
}
catch(Exception e)
{
if(_logger.IsErrorEnabled())
{
_logger.LogError(e, "An unhandeled exception occured");
}
return StatusCode(500, "An internal Server Error occured");
}
}
[HttpPost]
[Route("/index-documents")]
public async Task<IActionResult> IndexDocuments([FromBody] List<CodeSearchDocumentDto> codeSearchDocuments, CancellationToken cancellationToken)
{
_logger.TraceMethodEntry();
try
{
var documents = CodeSearchDocumentConverter.Convert(codeSearchDocuments);
var bulkIndexResponse = await _elasticsearchClient.BulkIndexAsync(documents, cancellationToken);
if (!bulkIndexResponse.IsSuccess())
{
if(_logger.IsErrorEnabled())
{
bulkIndexResponse.TryGetOriginalException(out var originalException);
_logger.LogError(originalException, "Indexing failed due to an invalid response from Elasticsearch");
}
return BadRequest($"ElasticSearch indexing failed with Errors");
}
return Ok();
}
catch (Exception e)
{
if (_logger.IsErrorEnabled())
{
_logger.LogError(e, "Failed to index documents");
}
return StatusCode(500);
}
}
}
}
The Converters used to translate between the Domain model and Data Transfer Objects are uninteresting, except for
the CodeSearchResultConverter. The CodeSearchResultConverter is responsible to convert from an Elasticsearch
SearchResponse<CodeSearchDocument> to a CodeSearchResultDto and also include the highlighted code.
public static class CodeSearchResultConverter
{
public static List<CodeSearchResultDto> Convert(SearchResponse<CodeSearchDocument> source)
{
List<CodeSearchResultDto> results = new List<CodeSearchResultDto>();
foreach (var hit in source.Hits)
{
if (hit.Source == null)
{
continue;
}
var result = new CodeSearchResultDto
{
Id = hit.Source.Id,
Owner = hit.Source.Owner,
Repository = hit.Source.Repository,
Filename = hit.Source.Filename,
Path = hit.Source.Path,
Permalink = hit.Source.Permalink,
LatestCommitDate = hit.Source.LatestCommitDate,
Content = GetContent(hit.Highlight),
};
results.Add(result);
}
return results;
}
private static List<HighlightedContentDto> GetContent(IReadOnlyDictionary<string, IReadOnlyCollection<string>>? highlight)
{
if (highlight == null)
{
return new();
}
highlight.TryGetValue("content", out var matchesForContent);
if(matchesForContent == null)
{
return new();
}
var match = matchesForContent.FirstOrDefault();
if (match == null)
{
return new();
}
var highlightedContent = ElasticsearchUtils.GetHighlightedContent(match);
return HighlightedContentConverter.Convert(highlightedContent);
}
}
The ElasticsearchUtils are a small helper class to extract the 5 matching lines from Elasticsearch
highlighted matches. It is extensively commented, so each line is well explained. I am sure it can
be made more performant, but it works...
// Licensed under the MIT license. See LICENSE file in the project root for full license information.
using ElasticsearchCodeSearch.Models;
using System.Text.RegularExpressions;
namespace ElasticsearchCodeSearch.Elasticsearch
{
public static class ElasticsearchUtils
{
/// <summary>
/// Matches all content between a start and an end tag.
/// </summary>
private static readonly Regex regex = new Regex($"{ElasticsearchConstants.HighlightStartTag}(.*){ElasticsearchConstants.HighlightEndTag}");
/// <summary>
/// Returns the Highlighted Content, with the line number, line content and the
/// information wether to highlight a line or not.
/// </summary>
/// <param name="content">Matching Content from the Elasticsearch response</param>
/// <returns>List of highlighted content</returns>
public static List<HighlightedContent> GetHighlightedContent(string content)
{
// We want to highlight entire lines of code and don't want to only
// highlight the match. So we need to get the number of matched lines
// to highlight first:
int matchedLinesCount = GetMatchedLinesCount(content);
// We now want to process each line separately. We don't need to scale
// massively, so we read the entire file content into memory. This won't
// be too much hopefully ...
var lines = content.Split(new string[] { "\n", "\r\n" }, StringSplitOptions.None);
// We need to know the total number of lines, so we know the maximum number of lines,
// that we can take and highlight:
int totalLines = lines.Length;
// Now we need the start index, we begin the highlightning at:
bool highlightFound = TryGetHighlightStartIndex(lines, out var startIdx);
// Holds the Search Results:
var result = new List<HighlightedContent>();
// If no highlight was found, we return an empty list, because there is
// nothing to highlight in the results anyway. Probably the filename
// matched?
if (!highlightFound)
{
return result;
}
// If there are at least 2 preceeding lines, we will
// use the two preceeding lines in the snippet.
int from = startIdx >= 2 ? startIdx - 2 : startIdx;
// If there are more than 2 lines left, we will use
// these trailing two lines in the snippet.
int to = totalLines - startIdx > 3 ? startIdx + 2 : startIdx;
// Build the result.
for (int lineIdx = from; lineIdx <= to; lineIdx++)
{
// The raw line with the possible match tags.
var line = lines[lineIdx];
// Remove the Start and End Tags from the content.
var sanitizedLine = line
.Replace(ElasticsearchConstants.HighlightStartTag, string.Empty)
.Replace(ElasticsearchConstants.HighlightEndTag, string.Empty);
// Check if this line has been a match. We could probably simplify the code
// but I don't know.
bool isHighlight = lineIdx >= startIdx && lineIdx < startIdx + matchedLinesCount;
result.Add(new HighlightedContent
{
LineNo = lineIdx + 1,
IsHighlight = isHighlight,
Content = sanitizedLine
});
}
return result;
}
private static int GetMatchedLinesCount(string content)
{
var match = regex.Match(content);
if (match.Groups.Count == 0)
{
// Just return 5 lines by default...
return 0;
}
string matchedContent = match.Groups[1].Value;
int matchedLinesCount = matchedContent
.Split(new string[] { "\n", "\r\n" }, StringSplitOptions.RemoveEmptyEntries)
.Length;
return matchedLinesCount;
}
private static bool TryGetHighlightStartIndex(string[] lines, out int startIdx)
{
startIdx = 0;
for (int lineIdx = 0; lineIdx < lines.Length; lineIdx++)
{
var line = lines[lineIdx];
if (line.Contains(ElasticsearchConstants.HighlightStartTag))
{
startIdx = lineIdx;
return true;
}
}
return false;
}
}
}
Creating the initial CodeSearch index
You might wonder how the index is created. This is done by implementing an IHostedService, which waits
for the Elasticsearch Node and checks if the index already exists. If it doesn't exist, the index is created
using the ElasticCodeSearchClient.
// Licensed under the MIT license. See LICENSE file in the project root for full license information.
using ElasticsearchCodeSearch.Elasticsearch;
using ElasticsearchCodeSearch.Shared.Logging;
namespace ElasticsearchCodeSearch.Hosting
{
/// <summary>
/// Used to create the Elasticsearch index at Startup.
/// </summary>
public class ElasticsearchInitializerHostedService : IHostedService
{
private readonly ElasticCodeSearchClient _elasticsearchClient;
private readonly ILogger<ElasticsearchInitializerHostedService> _logger;
public ElasticsearchInitializerHostedService(ILogger<ElasticsearchInitializerHostedService> logger, ElasticCodeSearchClient elasticsearchClient)
{
_logger = logger;
_elasticsearchClient = elasticsearchClient;
}
public async Task StartAsync(CancellationToken cancellationToken)
{
_logger.TraceMethodEntry();
var healthTimeout = TimeSpan.FromSeconds(60);
if (_logger.IsDebugEnabled())
{
_logger.LogDebug("Waiting for at least 1 Node and at least 1 Active Shard, with a Timeout of {HealthTimeout} seconds.", healthTimeout.TotalSeconds);
}
var clusterHealthResponse = await _elasticsearchClient.WaitForClusterAsync(healthTimeout, cancellationToken);
if (!clusterHealthResponse.IsValidResponse)
{
_logger.LogError("Invalid Request to get Cluster Health: {DebugInformation}", clusterHealthResponse.DebugInformation);
}
var indexExistsResponse = await _elasticsearchClient.IndexExistsAsync(cancellationToken);
if (!indexExistsResponse.Exists)
{
await _elasticsearchClient.CreateIndexAsync(cancellationToken);
}
}
public Task StopAsync(CancellationToken cancellationToken)
{
_logger.TraceMethodEntry();
return Task.CompletedTask;
}
}
}
The Service needs to be registered of course:
// Add Hosted Services
builder.Services.AddHostedService<ElasticsearchInitializerHostedService>();
Conclusion
In this article we have written a Code Search Service, that creates an Elasticsearch Index and allows to bulk index documents. We have also added the functionality to query for code, and return the highlighted match.
You can now open the Swagger page and play around with it:
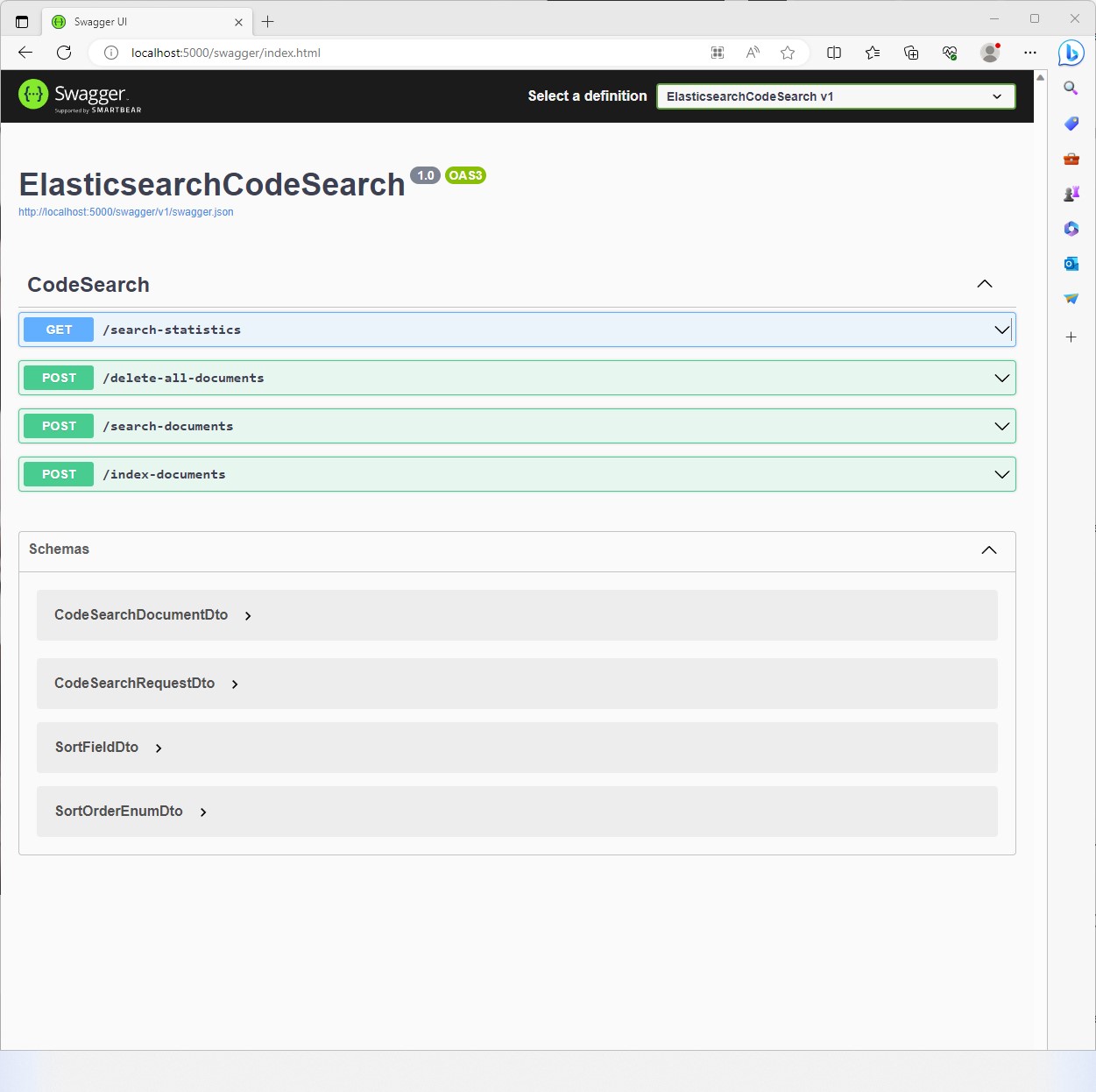
But whoops, there is nothing in the index yet! No worries, in the next article we will learn how to write an indexer and feed the Code Search Service with documents.