Our two beautiful girls were born in October 2019 and surprise, surprise, my sleep and freetime budget took a cut. And in between changing diapers and singing German Kinderlieder, I had a lot of time to think about projects.
And something that's been on my mind for a long, long time is to learn about Linked Data and Semantic Web Technologies.
So?
Let's do it!
About the Project
Every project starts with an idea. I have worked with weather data and airline data extensively, so the idea is to use a Triplestore to infer knowledge about Aviation data, using information from:
- Aircrafts
- Airports
- Carriers
- Flights
- Weather Stations
- ASOS / METAR Weather Data
Apache Jena will be used as the Triplestore implementation:
Apache Jena (or Jena in short) is a free and open source Java framework for building semantic web and Linked Data applications. The framework is composed of different APIs interacting together to process RDF data.
You can find all code and a guide on how to build the datasets in my GitHub Repository at:
What this Project is about
In the internet you seldomly get an idea how to really read, transform, import and query a dataset. Most scientific papers you find in the area of Semantic Web don't share their data, don't share their queries and they often do not explain how to recreate the results.
This article will focus on:
- Building a RDF dataset using .NET and libraries
- Creating an Apache Jena TDB2 database
- Efficiently importing the RDF dataset to Apache Jena TDB2
- Use the SPARQL language to query the dataset
What this Project is not about
It's not an introduction.
The article and the project are not a formal introduction to the Semantic Web and Linked Data. It won't go into all details, because there are already many, many, many great articles to RDF, OWL and Semantic Web Technologies in the internet.
https://programminghistorian.org has two articles I highly recommend reading:
- https://programminghistorian.org/en/lessons/intro-to-linked-data
- https://programminghistorian.org/en/lessons/retired/graph-databases-and-SPARQL
It's not about Ontologies.
This project doesn't implement ontologies, so there is no inference and reasoning. This is maybe an interesting area for later articles on Semantic Web Technologies.
If you are interested in a complete Air Traffic Ontology I recommend researching the The NASA Air Traffic Management Ontology (atmonto) to get an idea, what an ontology for the domain might look like:
It's not about benchmarks.
My past articles on Graph Databases focused on the performance of the database systems (see articles on SQL Server 2017 and Neo4j). These comparisms are often unfair and very misleading. Why was the SQL Server 2017 Graph Database so fast? Because its Columnstore compression algorithms make it possible to fit the entire dataset into RAM. Once the datasets get bigger and systems hit the SSD / HDD, we will see very different results.
Fair benchmarks are hard to create and this article intentionally doesn't compare systems anymore.
Datasets
In this article I will use several open datasets and show how to parse and import them to an Apache Jena database. I am unable to share the entire dataset, but I have described all steps neccessary to reproduce the article in the subfolders of:
I am using data from 2014, because this allows me to draw conclusions against the following previous Graph Database articles:
- Learning Neo4j at Scale: The Airline On Time Performance Dataset
- Analyzing Flight Data with the SQL Server 2017 Graph Database
Airline On Time Performance (AOTP)
Is a flight delayed or has been cancelled? The National Transportation Safety Board (NTSB) provides the so called Airline On Time Performance dataset that contains:
[...] on-time arrival data for non-stop domestic flights by major air carriers, and provides such additional items as departure and arrival delays, origin and destination airports, flight numbers, scheduled and actual departure and arrival times, cancelled or diverted flights, taxi-out and taxi-in times, air time, and non-stop distance.
The data spans a time range from October 1987 to present, and it contains more than 150 million rows of flight informations. It can be obtained as CSV files from the Bureau of Transportation Statistics Database, and requires you to download the data month by month:
More conveniently the Revolution Analytics dataset repository contains a ZIP File with the CSV data from 1987 to 2012.
ASOS / AWOS Weather
Is a flight delayed, because of weather events? Many airports in the USA have so called Automated Surface Observing System (ASOS) units, that are designed to serve aviation and meterological operations.
The NOAA website writes on ASOS weather stations:
Automated Surface Observing System (ASOS) units are automated sensor suites that are designed to serve meteorological and aviation observing needs. There are currently more than 900 ASOS sites in the United States. These systems generally report at hourly intervals, but also report special observations if weather conditions change rapidly and cross aviation operation thresholds.
ASOS serves as a primary climatological observing network in the United States. Not every ASOS is located at an airport; for example, one of these units is located at Central Park in New York City. ASOS data are archived in the Global Surface Hourly database, with data from as early as 1901.
But where can we get the data from and correlate it with airports? The Iowa State University hosts an archive of automated airport weather observations:
The IEM maintains an ever growing archive of automated airport weather observations from around the world! These observations are typically called 'ASOS' or sometimes 'AWOS' sensors. A more generic term may be METAR data, which is a term that describes the format the data is transmitted as. If you don't get data for a request, please feel free to contact us for help. The IEM also has a one minute interval dataset for Iowa ASOS (2000-) and AWOS (1995-2011) sites. This archive simply provides the as-is collection of historical observations, very little quality control is done. "M" is used to denote missing data.
The Iowa State University also provides a Python script to download the ASOS / AWOS data:
NCAR Weather Station List
What type of weather station are the measurements from? What is the name of the weather station? What is its exact location?
We could compile a list of stations from files in the Historical Observing Metadata Repository:
But while browsing the internet I found a list of stations, that contains all information we need. And I am allowed to use it with the permission of the author. I uploaded the latest version of June 2019 into my GitHub repository, because I needed to make very minor modifications to the original file:
FAA Aircraft Registry
Which aircraft was the flight on? Which engines have been used?
Every airplane in the world has a so called N-Number, that is issued by the Federal Aviation Administration (FAA).
The FAA maintains the Aircraft Registry Releasable Aircraft Database:
[...]
The archive file contains the:
- Aircraft Registration Master file
- Aircraft Dealer Applicant file
- Aircraft Document Index file
- Aircraft Reference file by Make/Model/Series Sequence
- Deregistered Aircraft file
- Engine Reference file
- Reserve N-Number file
Files are updated each federal business day. The records in each database file are stored in a comma delimited format (CDF) and can be manipulated by common database management applications, such as MS Access.
It is available at:
I have used some Excel-magic to join the several files into one and export a CSV File, that strips all sensitive data off and could be parsed easily:
Apache Jena, RDF
RDF
The W3C has defined the Resource Descirption Framework (RDF) to represent semantic information on the Web. The W3C RDF Primer explains:
The Resource Description Framework (RDF) is a framework for representing information in the Web. This document defines an abstract syntax (a data model) which serves to link all RDF-based languages and specifications. The abstract syntax has two key data structures: RDF graphs are sets of subject-predicate-object triples, where the elements may be IRIs, blank nodes, or datatyped literals. They are used to express descriptions of resources. RDF datasets are used to organize collections of RDF graphs, and comprise a default graph and zero or more named graphs. RDF 1.1 Concepts and Abstract Syntax also introduces key concepts and terminology, and discusses datatyping and the handling of fragment identifiers in IRIs within RDF graphs.
The takeaway (for me) is: RDF represents information as a series of subject - predicate - object statements, called Triples. So looking at our dataset a statement about the origin of a flight might look like this:
<Flight N965UW> <has origin airport> <Airport LAX>
Here the subject is <Flight N965UW>, the object is <Airport LAX> and <has origin airport> is the predicate,
that defines the relationship between the two nodes. These Triples can be stored in so called Triplestores optimized
for storage and retrieval of Triples.
Apache Jena
These Triples are stored using a Triplestore. Apache Jena provides TDB2 as its Triplestore implementation and a stand-alone server called Apache Fuseki:
Apache Jena Fuseki is a SPARQL server. It can run as a operating system service, as a Java web application (WAR file), and as a standalone server. It provides security (using Apache Shiro) and has a user interface for server monitoring and administration.
It provides the SPARQL 1.1 protocols for query and update as well as the SPARQL Graph Store protocol.
Fuseki is tightly integrated with TDB to provide a robust, transactional persistent storage layer, and incorporates Jena text query. It can be used to provide the protocol engine for other RDF query and storage systems.
What needs to be done for this project is:
- Define a SPARQL data service
- Define TDB2 dataset definition
In Apache Jena this is done by writing a so called "Fuseki Configuration File", that is written in the RDF Turtle syntax:
The configuration file for our aviationService now looks like this:
## Fuseki Server configuration file.
@prefix : <#> .
@prefix fuseki: <http://jena.apache.org/fuseki#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix tdb2: <http://jena.apache.org/2016/tdb#> .
@prefix ja: <http://jena.hpl.hp.com/2005/11/Assembler#> .
[] rdf:type fuseki:Server ;
fuseki:services (
<#aviationService>
) .
<#aviationService> rdf:type fuseki:Service ;
fuseki:name "aviation" ;
fuseki:serviceQuery "sparql" ;
fuseki:serviceQuery "query" ;
fuseki:serviceUpdate "update" ;
fuseki:serviceUpload "upload" ;
fuseki:serviceReadWriteGraphStore "data" ;
fuseki:serviceReadGraphStore "get" ;
fuseki:dataset <#dataset> .
<#dataset> rdf:type tdb2:DatasetTDB2;
tdb2:location "/Apache_Jena/data/aviation" ;
##tdb2:unionDefaultGraph true ;
Please note, that you probably have to change the filesystem location in the above configuration:
tdb2:location "YOUR FILESYSTEM PATH HERE" ;
The Apache Fuseki standalone server is started with the --conf switch using the custom Fuseki
configuration. The GitHub Repository contains a Batch Script, that sets the Directories and starts
the service:
@echo off
:: Copyright (c) Philipp Wagner. All rights reserved.
:: Licensed under the MIT license. See LICENSE file in the project root for full license information.
set FUSEKI_SERVER_DIRECTORY="G:\Apache_Jena\apache-jena-fuseki-3.13.1"
set AVIATION_SERVICE_CONFIGURATION="D:\github\ApacheJenaSample\Scripts\config\aviation_conf.ttl"
pushd %FUSEKI_SERVER_DIRECTORY%
java -Xmx1200M -jar "%FUSEKI_SERVER_DIRECTORY%\fuseki-server.jar" --conf=%AVIATION_SERVICE_CONFIGURATION%
pause
Parsing the Datasets
Apache Jena has been setup and is running! But it doesn't contain any data yet.
In this section we will take a look at how to go from many CSV files to a RDF file.
From CSV to .NET
A lot of datasets in the wild are given as CSV files. Although there is a RFC 4180, the standard only defines the structure of a line in the CSV data (think of newline characters, delimiters, Quoted Data, ...).
A CSV file doesn't have something like defined formats, think of:
- Date formats
- Culture-specific formatting
- Text Representation of missing values
- Text Representation of duration (Milliseconds, Seconds, Minutes, ...)
- ...
In any data-driven project most of the time goes into:
- Analyzing
- Preprocessing
- Normalizing
- Parsing
To simplify and speed up CSV parsing I wrote TinyCsvParser some years ago. As a library author it's important to eat your own dogfood and it makes good example to show how I would approach such data.
Basically I structure the CSV parsing for every dataset in its own project, like this:
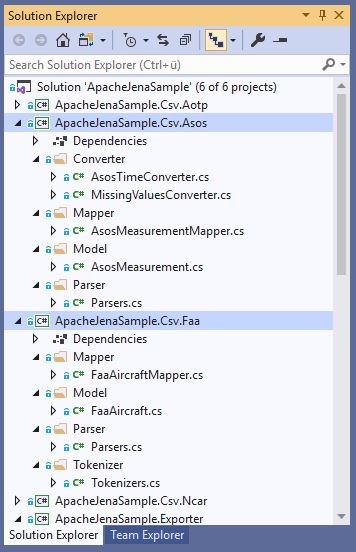
This leads to a nice separation of concerns:
- Converter
- Provides Converters to parse Dataset-specific values / formats
- Mapper
- Defines the Mapping between the CSV File and the C# Domain Model
- Model
- Contains the C# Domain Model
- Parser
- Provides the Parsers with information about:
- Should the header be skipped?
- Which Column Delimiter should be used?
- Which Mapping should be used?
- Provides the Parsers with information about:
- Tokenizer
- Defines how to tokenize the CSV data:
- Is a
string.Split(...)sufficient for the data (saves CPU cycles)? - Is it a fixed-width format?
- Is a
- Defines how to tokenize the CSV data:
From .NET to RDF
There is a great .NET library for working with all kinds of RDF data called dotNetRDF:
The dotNetRDF website writes:
dotNetRDF is...
- A complete library for parsing, managing, querying and writing RDF.
- A common .NET API for working with RDF triple stores such as AllegroGraph, Jena, Stardog and Virtuoso.
- A suite of command-line and GUI tools for working with RDF under Windows
- Free (as in beer) and Open Source (as in freedom) under a permissive MIT license
While very advanced and complete, I need dotNetRDF primarly for writing RDF data.
In the Core Concepts of the dotNetRDF documentation:
We can see there are basically 3 Key Interfaces called INode, IGraph and ITripleStore.
This project only uses INode implementations for writing the various Node types defined by the RDF specification. I
initially tried to use its Apache Fuseki connector and while it works... it is way to slow for loading a billion
triples.
See... there are several ways to use dotNetRDF for building the RDF data and mine shouldn't be the preferred one. If you
only have a small amount of data, then the best approach is to use an IGraph implementation. Create an in-memory
representation of a graph and use the built-in serialization methods to write a file.
The Aviation dataset is large, so I decided to only use very specific parts of dotNetRDF.
Creating RDF Nodes
We saw, that RDF data contains several Node types like Literal Nodes, Blank Nodes, URI Nodes. To create the several kind
of nodes dotNetRDF has a NodeFactory. To simplify the instantiation of nodes I started with writing a set of extension
methods for the INodeFactory:
public static class DotNetRdfHelpers
{
public static INode AsVariableNode(this INodeFactory nodeFactory, string value)
{
return nodeFactory.CreateVariableNode(value);
}
public static INode AsUriNode(this INodeFactory nodeFactory, Uri uri)
{
return nodeFactory.CreateUriNode(uri);
}
public static INode AsLiteralNode(this INodeFactory nodeFactory, string value)
{
return nodeFactory.CreateLiteralNode(value);
}
public static INode AsLiteralNode(this INodeFactory nodeFactory, string value, string langspec)
{
return nodeFactory.CreateLiteralNode(value, langspec);
}
public static INode AsBlankNode(this INodeFactory nodeFactory, string nodeId)
{
return nodeFactory.CreateBlankNode(nodeId);
}
public static INode AsValueNode(this INodeFactory nodeFactory, object value)
{
if (value == null)
{
return null;
}
switch (value)
{
case Uri uriValue:
return nodeFactory.CreateUriNode(uriValue);
case bool boolValue:
return new BooleanNode(null, boolValue);
case byte byteValue:
return new ByteNode(null, byteValue);
case DateTime dateTimeValue:
return new DateTimeNode(null, dateTimeValue);
case DateTimeOffset dateTimeOffsetValue:
return new DateTimeNode(null, dateTimeOffsetValue);
case decimal decimalValue:
return new DecimalNode(null, decimalValue);
case double doubleValue:
return new DoubleNode(null, doubleValue);
case float floatValue:
return new FloatNode(null, floatValue);
case long longValue:
return new LongNode(null, longValue);
case int intValue:
return new LongNode(null, intValue);
case string stringValue:
return new StringNode(null, stringValue, UriFactory.Create(XmlSpecsHelper.XmlSchemaDataTypeString));
case char charValue:
return new StringNode(null, charValue.ToString(), UriFactory.Create(XmlSpecsHelper.XmlSchemaDataTypeString));
case TimeSpan timeSpanValue:
return new TimeSpanNode(null, timeSpanValue);
default:
throw new InvalidOperationException($"Can't convert type {value.GetType()}");
}
}
}
In the code we can then write this to create a literal node for a given property:
nodeFactory.AsValueNode(aircraft.EngineHorsepower)
I wrote a small class TripleBuilder to provide a somewhat "fluent" way of creating the list
of Triples, because a subject is often associated with a large number of predicates:
public class TripleBuilder
{
private readonly INode subj;
private readonly List<Triple> triples;
public TripleBuilder(INode subj)
{
this.subj = subj;
this.triples = new List<Triple>();
}
public TripleBuilder Add(INode pred, INode obj)
{
if (obj == null)
{
return this;
}
triples.Add(new Triple(subj, pred, obj));
return this;
}
public TripleBuilder AddWithSubject(INode subj, INode pred, INode obj)
{
if (obj == null)
{
return this;
}
triples.Add(new Triple(subj, pred, obj));
return this;
}
public List<Triple> Build()
{
return triples;
}
}
About Namespaces
Previously I said a Triple might look like this:
<Flight N965UW> <has origin airport> <Airport LAX>
But in reality it looks more like this:
<http://www.bytefish.de/aviation/Flight#N965UW> <http://www.bytefish.de/aviation/Flight#flight_date> "2014-03-18T00:54:00"^^<http://www.w3.org/2001/XMLSchema#dateTime>
<http://www.bytefish.de/aviation/Flight#N965UW> <http://www.bytefish.de/aviation/Flight#origin> <http://www.bytefish.de/aviation/Airports#LAX>
Uh. We can see some things here.
First the Flight date is represented as "2014-03-18T00:54:00", which is called a "Literal Node". A Literal Node can have a data type,
in the snippet it is a dateTime. The Airport LAX is a URI, which means it is a "URI Node" with a unique identifier, which can
be referenced as an Object by other nodes.
Full qualified namespaces such as http://www.bytefish.de/aviation/Flight#N965UW are obviously a pain to work with. You cannot get
a quick overview of the data and it's easy to introduce errors without any sufficiently advanced editor. And it is redundant information,
that blows up the intermediate RDF file we are going to write.
To fix this issue RDF introduces "Prefixes". Using Prefixes we could write the above snippet as:
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX f: <http://www.bytefish.de/aviation/Flight#>
f:N965UW f:flight_date "2014-03-18T00:54:00"^^xsd:dateTime
f:N965UW f:origin f:LAX
dotNetRDF has a NamespaceMapper to provide this functionality.
I have put all URI namespaces in a class Constants:
// We don't want to write the full URL for every
// triple, because that will lead to a large TTL
// file with redundant data:
var namespaceMapper = new NamespaceMapper();
namespaceMapper.AddNamespace("ge", Constants.NsAviationGeneral);
namespaceMapper.AddNamespace("ap", Constants.NsAviationAirport);
namespaceMapper.AddNamespace("ac", Constants.NsAviationtAircraft);
namespaceMapper.AddNamespace("ca", Constants.NsAviationCarrier);
namespaceMapper.AddNamespace("fl", Constants.NsAviationFlight);
namespaceMapper.AddNamespace("we", Constants.NsAviationWeather);
namespaceMapper.AddNamespace("st", Constants.NsAviationWeatherStation);
Something good to know: dotNetRDF caches all URIs, which improves performance for in-memory ITripleStore
implementations. It isn't neccessary for our dataset, because we can guarantee a unique identifier for all
nodes and I saw the memory exploding.
So instead we implement a simple non-caching version of the mapper used by dotNetRDF:
public class NonCachingQNameOutputMapper : QNameOutputMapper
{
public NonCachingQNameOutputMapper(INamespaceMapper nsmapper)
: base(nsmapper)
{
}
protected override void AddToCache(string uri, QNameMapping mapping)
{
// Ignore Caching ...
}
}
Using Turtle instead of RDF/XML
RDF can be represented in a wide range of formats, such as XML, JSON, N3, Turtle, ... I decided to go for Turtle:
So what we will do in dotNetRDF is to create a formatter for Turtle:
// Create the TurtleFormatter with the Namespace Mappings:
var turtleFormatter = new TurtleFormatter(outputMapper);
Parsing and Converting the Data
Then we can start with parsing the CSV data using the CSV Parsers defined.
In the following snippet we are reading the FAA Aircraft Dataset:
private static ParallelQuery<AircraftDto> GetAircraftData(string filename)
{
return Csv.Faa.Parser.Parsers.FaaAircraftParser
// Parse as ASCII file:
.ReadFromFile(filename, Encoding.ASCII)
// Only use valid lines:
.Where(x => x.IsValid)
// Get the Result:
.Select(x => x.Result)
// Get AircraftDto with a unique ID:
.Select(x => new AircraftDto
{
AircraftManufacturer = x.AircraftManufacturer,
AircraftModel = x.AircraftModel,
AircraftSeats = x.AircraftSeats,
EngineHorsepower = x.EngineHorsepower,
EngineManufacturer = x.EngineManufacturer,
EngineModel = x.EngineModel,
EngineThrust = x.EngineThrust,
N_Number = x.N_Number?.Trim('N'),
SerialNumber = x.SerialNumber,
UniqueId = x.UniqueId
});
}
The Csv.Faa.Model.Aircraft is converted into a AircraftDto. Why? Because each Aircraft is going to be a subject in
the Graph. It can be referenced by other nodes and so every aircraft needs a URI that can be referenced. What I did here is to
simply duplicate the CSV Model and add a Property Uri to each entity, that returns an URI:
// Copyright (c) Philipp Wagner. All rights reserved.
// Licensed under the MIT license. See LICENSE file in the project root for full license information.
using ApacheJenaSample.Exporter.Extensions;
using System;
using System.Xml;
namespace ApacheJenaSample.Exporter.Dto
{
public class AircraftDto
{
public Uri Uri => UriHelper.SetFragment(Constants.NsAviationtAircraft, XmlConvert.EncodeName($"aircraft_{N_Number}"));
public string N_Number { get; set; }
public string SerialNumber { get; set; }
public string UniqueId { get; set; }
public string AircraftManufacturer { get; set; }
public string AircraftModel { get; set; }
public string AircraftSeats { get; set; }
public string EngineManufacturer { get; set; }
public string EngineModel { get; set; }
public float? EngineHorsepower { get; set; }
public float? EngineThrust { get; set; }
}
}
See how I used XmlConvert.EncodeName to replace special characters with valid values.
Writing RDF Triples to a File
Everything is in place to actually write the Triples into a file. The file starts with writing the
PREFIX statements and then goes on to convert the AirportDto into the list of Triples. These
triples are then written to a FileStream using the TurtleFormatter.
public static void Main(string[] args)
{
// ...
var aircrafts = GetAircraftData(csvAircraftsFile).ToList();
using (FileStream fileStream = File.Create(@"G:\aviation_2014.ttl"))
{
using (StreamWriter writer = new StreamWriter(fileStream))
{
WriteNamespaces(writer);
WriteAircrafts(writer, aircrafts);
// Write more data ...
}
}
}
private static void WriteNamespaces(StreamWriter writer)
{
var namespaceMappings = namespaceMapper.Prefixes
.ToDictionary(x => x, x => namespaceMapper.GetNamespaceUri(x));
foreach (var namespaceMapping in namespaceMappings)
{
var formattedNamespaceMapping = turtleFormatter.FormatNamespace(namespaceMapping.Key, namespaceMapping.Value);
writer.WriteLine(formattedNamespaceMapping);
}
writer.WriteLine();
}
private static void WriteAircrafts(StreamWriter streamWriter, IEnumerable<AircraftDto> aircrafts)
{
foreach (var triple in aircrafts.SelectMany(x => ConvertAircraft(x)))
{
WriteTriple(streamWriter, triple);
}
}
private static List<Triple> ConvertAircraft(AircraftDto aircraft)
{
return new TripleBuilder(nodeFactory.AsUriNode(aircraft.Uri))
.Add(nodeFactory.AsUriNode(Constants.Predicates.Type), nodeFactory.AsValueNode(Constants.Types.Aircraft))
.Add(nodeFactory.AsUriNode(Constants.Predicates.AircraftEngineHorsepower), nodeFactory.AsValueNode(aircraft.EngineHorsepower))
.Add(nodeFactory.AsUriNode(Constants.Predicates.AircraftEngineManufacturer), nodeFactory.AsValueNode(aircraft.EngineManufacturer))
.Add(nodeFactory.AsUriNode(Constants.Predicates.AircraftEngineModel), nodeFactory.AsValueNode(aircraft.EngineModel))
.Add(nodeFactory.AsUriNode(Constants.Predicates.AircraftEngineThrust), nodeFactory.AsValueNode(aircraft.EngineThrust))
.Add(nodeFactory.AsUriNode(Constants.Predicates.AircraftManufacturer), nodeFactory.AsValueNode(aircraft.AircraftManufacturer))
.Add(nodeFactory.AsUriNode(Constants.Predicates.AircraftModel), nodeFactory.AsValueNode(aircraft.AircraftModel))
.Add(nodeFactory.AsUriNode(Constants.Predicates.AircraftN_Number), nodeFactory.AsValueNode(aircraft.N_Number))
.Add(nodeFactory.AsUriNode(Constants.Predicates.AircraftSeats), nodeFactory.AsValueNode(aircraft.AircraftSeats))
.Add(nodeFactory.AsUriNode(Constants.Predicates.AircraftSerialNumber), nodeFactory.AsValueNode(aircraft.SerialNumber))
.Add(nodeFactory.AsUriNode(Constants.Predicates.AircraftUniqueId), nodeFactory.AsValueNode(aircraft.UniqueId))
.Build();
}
private static void WriteTriple(StreamWriter streamWriter, Triple triple)
{
var value = turtleFormatter.Format(triple);
streamWriter.WriteLine(value);
}
Importing the Dataset
So far we have parsed the CSV datasets and wrote a valid RDF/Turtle file. What's next is getting the
data into the TDB2 database. We could use SPARQL INSERT DATA statements to do this:
But there is a much faster and easier way using the Apache Jena tdb2.tdbloader:
The Apache Jena TDB FAQ writes:
tdbloader2 is POSIX compliant script based which limits it to running on POSIX systems only. The advantage this gives it is that it is capable of building the database files and indices directly without going through the Java API which makes it much faster. However this does mean that it can only be used for an initial database load since it does not know how to apply incremental updates. Using tdbloader2 on a pre-existing database will cause the existing database to be overwritten.
I am using a Windows system, so I will use the Batch Script provided in bat\tdb2_tdbloader.bat and write a small Batch Script:
@echo off
:: Copyright (c) Philipp Wagner. All rights reserved.
:: Licensed under the MIT license. See LICENSE file in the project root for full license information.
set JENA_HOME="G:\Apache_Jena\apache-jena-3.13.1"
set JENA_TDBLOADER2="%JENA_HOME%\bat\tdb2_tdbloader.bat"
set DATABASE_DIR="G:\Apache_Jena\data\aviation"
set DATASET="G:\aviation_2014.ttl"
pushd %JENA_HOME%
%JENA_TDBLOADER2% --loc=%DATABASE_DIR% %DATASET%
And that's it. Please note, that the above tdbloader does a so called phased import. It first loads the RDF data into TDB2
and then builds the indexes:
It uses multiple threads for both the initial loading (3 worker threads) and then 2 threads in parallel for building the other indexes.
Queries
Apache Fuseki Web Interface
Apache Fuseki comes with a web application, which is hosted at http://localhost:3030 for the stand-alone server:
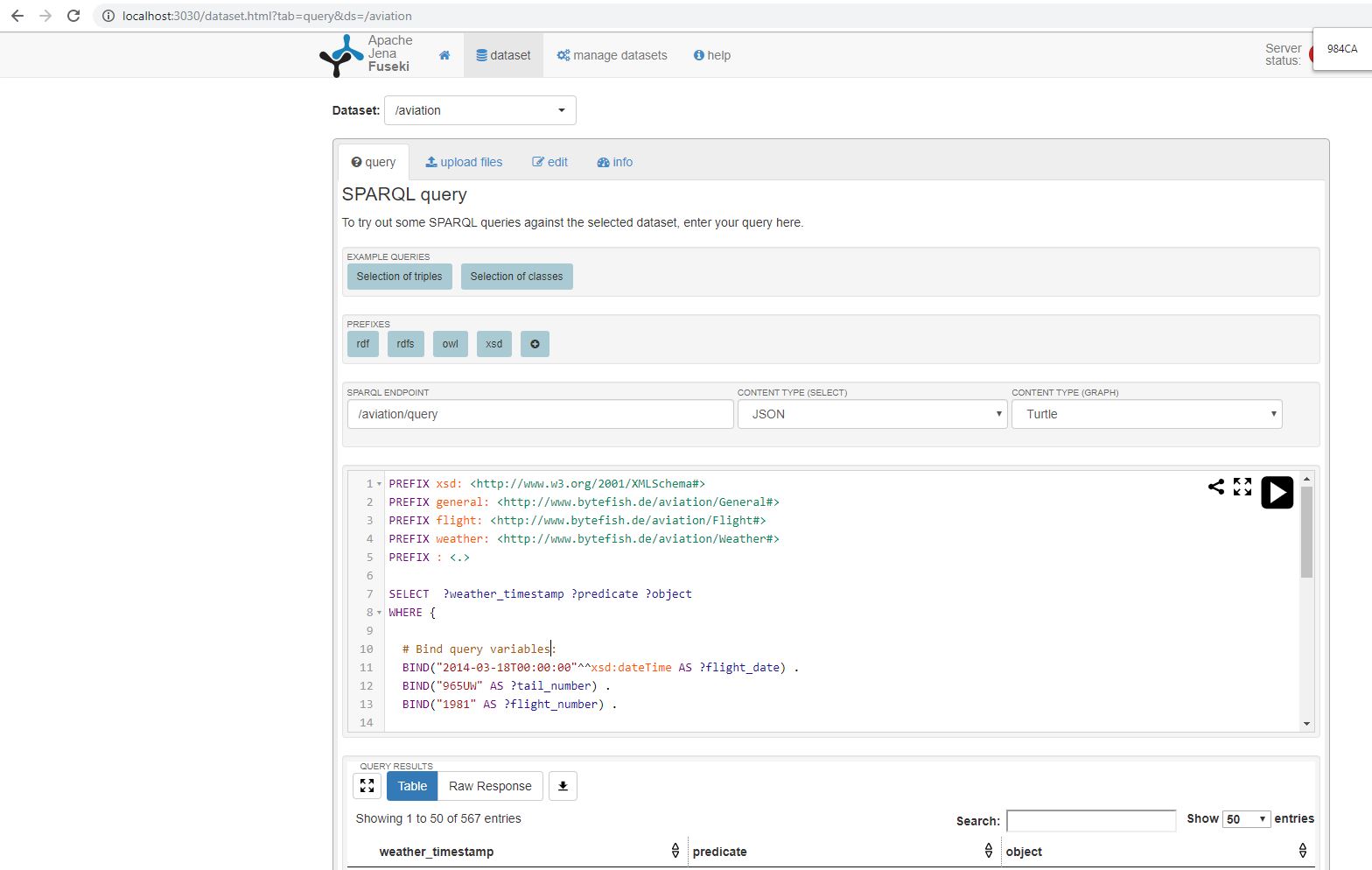
The web application has a nice editor to query the /aviation endpoint, which we will use for the following SPARQL queries.
Get all reachable Nodes for a given Flight
The following query returns all nodes reachable for a given flight. This is a great way to initially explore a dataset:
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX flight: <http://www.bytefish.de/aviation/Flight#>
PREFIX : <.>
CONSTRUCT { ?s ?p ?o }
WHERE {
?flight flight:tail_number "965UW" ;
flight:flight_number "1981" ;
flight:flight_date "2014-03-18T00:00:00"^^xsd:dateTime ;
(<>|!<>)* ?s .
?s ?p ?o
}
And we get back the following data:
@prefix : <http://server/unset-base/> .
@prefix flight: <http://www.bytefish.de/aviation/Flight#> .
@prefix st: <http://www.bytefish.de/aviation/WeatherStation#> .
@prefix ac: <http://www.bytefish.de/aviation/Aircraft#> .
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix fl: <http://www.bytefish.de/aviation/Flight#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix ge: <http://www.bytefish.de/aviation/General#> .
@prefix ca: <http://www.bytefish.de/aviation/Carrier#> .
@prefix we: <http://www.bytefish.de/aviation/Weather#> .
@prefix ap: <http://www.bytefish.de/aviation/Airport#> .
st:weather_station_PHL_KPHL
ge:node_type "weather_station" ;
st:elevation "18.0"^^xsd:float ;
st:iata "PHL" ;
st:icao "KPHL" ;
st:lat "39 52N" ;
st:lon "075 14W" ;
st:name "PHILADELPHIA" ;
st:synop "72408" .
fl:flight_1981_965UW_20140318_17_15
fl:actual_departure_time "PT17H26M"^^xsd:duration ;
fl:arrival_delay -1 ;
fl:day_of_month 18 ;
fl:day_of_week 2 ;
fl:departure_delay 11 ;
fl:distance "280.0"^^xsd:float ;
fl:flight_date "2014-03-18T00:00:00"^^xsd:dateTime ;
fl:flight_number "1981" ;
fl:month 3 ;
fl:scheduled_departure_time "PT17H15M"^^xsd:duration ;
fl:tail_number "965UW" ;
fl:year 2014 ;
ge:has_aircraft ac:aircraft_965UW ;
ge:has_carrier ca:carrier_US ;
ge:has_destination_airport ap:airport_BOS ;
ge:has_origin_airport ap:airport_PHL ;
ge:node_type "flight" .
ac:aircraft_965UW
ac:engine_horsepower "0.0"^^xsd:float ;
ac:engine_manufacturer "GE" ;
ac:engine_model "CF34-10E6" ;
ac:engine_thrust "18820.0"^^xsd:float ;
ac:manufacturer "EMBRAER" ;
ac:model "ERJ 190-100 IGW" ;
ac:n_number "965UW" ;
ac:seats "20" ;
ac:serial_number "19000198" ;
ac:unique_id "1008724" ;
ge:node_type "aircraft" .
ap:airport_PHL ap:airport_id "14100" ;
ap:city "Philadelphia, PA" ;
ap:country "United States" ;
ap:iata "PHL" ;
ap:name "Philadelphia International" ;
ap:state "Pennsylvania" ;
ge:has_weather_station st:weather_station_PHL_KPHL ;
ge:node_type "airport" .
st:weather_station_BOS_KBOS
ge:node_type "weather_station" ;
st:elevation "6.0"^^xsd:float ;
st:iata "BOS" ;
st:icao "KBOS" ;
st:lat "42 22N" ;
st:lon "071 01W" ;
st:name "BOSTON" ;
st:synop "72509" .
ca:carrier_US ca:code "US" ;
ca:description "US Airways Inc." ;
ge:node_type "carrier" .
ap:airport_BOS ap:airport_id "10721" ;
ap:city "Boston, MA" ;
ap:country "United States" ;
ap:iata "BOS" ;
ap:name "Logan International" ;
ap:state "Massachusetts" ;
ge:has_weather_station st:weather_station_BOS_KBOS ;
ge:node_type "airport" .
Get the Flights cancelled due to Weather
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX airport: <http://www.bytefish.de/aviation/Airport#>
PREFIX general: <http://www.bytefish.de/aviation/General#>
PREFIX flight: <http://www.bytefish.de/aviation/Flight#>
PREFIX weather: <http://www.bytefish.de/aviation/Weather#>
PREFIX : <.>
SELECT ?origin_iata ?destination_iata ?tail_number ?flight_number ?flight_date ?scheduled_departure ?cancellation_code
WHERE {
# Bind query variables:
BIND("B" AS ?cancellation_code) .
?origin airport:name ?origin_name ;
airport:iata ?origin_iata .
?destination airport:name ?destination_name ;
airport:iata ?destination_iata .
# Select the flight(s) with the bound variables:
?flight flight:cancellation_code ?cancellation_code ;
flight:tail_number ?tail_number ;
flight:flight_number ?flight_number ;
flight:flight_date ?flight_date ;
flight:scheduled_departure_time ?scheduled_departure ;
general:has_origin_airport ?origin ;
general:has_destination_airport ?destination .
}
ORDER BY ASC(?flight_date) ASC(?scheduled_departure)
LIMIT 10
This SPARQL query gives the following results:
"origin_iata" , "destination_iata" , "tail_number" , "flight_number" , "flight_date" , "scheduled_departure" , "cancellation_code" ,
"ORD" , "EWR" , , "1050" , "2014-01-01T00:00:00" , "PT5H" , "B" ,
"SEA" , "SFO" , "918SW" , "5639" , "2014-01-01T00:00:00" , "PT5H21M" , "B" ,
"CEC" , "SFO" , "223SW" , "5335" , "2014-01-01T00:00:00" , "PT5H29M" , "B" ,
"ORD" , "MIA" , "3KXAA" , "1270" , "2014-01-01T00:00:00" , "PT5H30M" , "B" ,
"ACV" , "SFO" , "290SW" , "5604" , "2014-01-01T00:00:00" , "PT5H31M" , "B" ,
"ORD" , "DEN" , , "1043" , "2014-01-01T00:00:00" , "PT5H40M" , "B" ,
"COD" , "DEN" , "705SK" , "5550" , "2014-01-01T00:00:00" , "PT5H45M" , "B" ,
"LNK" , "ORD" , , "6276" , "2014-01-01T00:00:00" , "PT5H48M" , "B" ,
"ORD" , "DFW" , "475AA" , "2301" , "2014-01-01T00:00:00" , "PT5H55M" , "B" ,
"SPI" , "ORD" , , "5462" , "2014-01-01T00:00:00" , "PT6H" , "B" ,
The query uncovers something interesting in the NTSB Data. For some of the cancelled flights, the tail number is missing. So
for a certain percentage of flights, we cannot say for sure which aircraft was grounded. An example is a United Airlines flight
on 2014-01-01:
2014,1,1,3,2014-01-01,"UA","","1050",13930,"ORD","IL",11618,"EWR","NJ","0500","",,,,,,"","",,"0804","",,,,,1.00,"B",0.00,124.00,,,1.00,719.00,3,,,,,,
Get the Weather Data for day of Flight
If a flight was grounded due to weather according to NAS, it will be interesting what the weather was at the time of flight. Have there been strong winds? Or what may have been the reason? The following query shows how to get the weather at the flights airport at time of day.
I am binding the ?flight_date, ?tail_number and the ?flight_number:
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX general: <http://www.bytefish.de/aviation/General#>
PREFIX flight: <http://www.bytefish.de/aviation/Flight#>
PREFIX weather: <http://www.bytefish.de/aviation/Weather#>
PREFIX : <.>
SELECT ?weather_timestamp ?predicate ?object
WHERE {
# Bind query variables:
BIND("2014-03-18T00:00:00"^^xsd:dateTime AS ?flight_date) .
BIND("965UW" AS ?tail_number) .
BIND("1981" AS ?flight_number) .
# Select the flight(s) with the bound variables:
?flight flight:tail_number ?tail_number ;
flight:flight_number ?flight_number ;
flight:flight_date ?flight_date ;
general:has_origin_airport ?origin .
# Get the Weather Station associated with the Airport:
?origin general:has_weather_station ?station .
# Get all predicates and objects for the Weather Station:
?weather general:has_station ?station ;
weather:timestamp ?weather_timestamp ;
?predicate ?object .
# But filter only for values of the given day:
FILTER( year(?weather_timestamp) = year(?flight_date)
&& month(?weather_timestamp) = month(?flight_date)
&& day(?weather_timestamp) = day(?flight_date))
}
ORDER BY ASC(?weather_timestamp)
LIMIT 50
This query gives us all weather measurements for the day of a specific flight:
"weather_timestamp" , "predicate" , "object" ,
"2014-03-18T00:54:00" , "http://www.bytefish.de/aviation/General#has_station" , "http://www.bytefish.de/aviation/WeatherStation#weather_station_PHL_KPHL" ,
"2014-03-18T00:54:00" , "http://www.bytefish.de/aviation/Weather#tmpc" , "-0.6" ,
"2014-03-18T00:54:00" , "http://www.bytefish.de/aviation/Weather#dwpc" , "-10.6" ,
"2014-03-18T00:54:00" , "http://www.bytefish.de/aviation/Weather#feelc" , "-5.122222" ,
"2014-03-18T00:54:00" , "http://www.bytefish.de/aviation/Weather#lon" , "-75.2311" ,
"2014-03-18T00:54:00" , "http://www.bytefish.de/aviation/Weather#p01i" , "0.0" ,
"2014-03-18T00:54:00" , "http://www.bytefish.de/aviation/Weather#vsby_mi" , "10.0" ,
"2014-03-18T00:54:00" , "http://www.bytefish.de/aviation/Weather#mslp" , "1019.4" ,
"2014-03-18T00:54:00" , "http://www.bytefish.de/aviation/Weather#dwpf" , "12.92" ,
"2014-03-18T00:54:00" , "http://www.bytefish.de/aviation/Weather#vsby_km" , "16.09344" ,
"2014-03-18T00:54:00" , "http://www.bytefish.de/aviation/Weather#timestamp" , "2014-03-18T00:54:00" ,
"2014-03-18T00:54:00" , "http://www.bytefish.de/aviation/Weather#feelf" , "22.78" ,
"2014-03-18T00:54:00" , "http://www.bytefish.de/aviation/Weather#alti" , "30.11" ,
"2014-03-18T00:54:00" , "http://www.bytefish.de/aviation/Weather#tmpf" , "30.92" ,
"2014-03-18T00:54:00" , "http://www.bytefish.de/aviation/Weather#lat" , "39.8683" ,
"2014-03-18T00:54:00" , "http://www.bytefish.de/aviation/Weather#relh" , "46.74" ,
"2014-03-18T00:54:00" , "http://www.bytefish.de/aviation/Weather#drct" , "70.0" ,
"2014-03-18T00:54:00" , "http://www.bytefish.de/aviation/Weather#skyl1" , "7000.0" ,
"2014-03-18T00:54:00" , "http://www.bytefish.de/aviation/Weather#sknt" , "8.0" ,
"2014-03-18T00:54:00" , "http://www.bytefish.de/aviation/Weather#metar" , "KPHL 180054Z 07008KT 10SM OVC070 M01/M11 A3011 RMK AO2 SLP194 T10061106" ,
"2014-03-18T00:54:00" , "http://www.bytefish.de/aviation/Weather#skyc1" , "OVC" ,
"2014-03-18T00:54:00" , "http://www.bytefish.de/aviation/Weather#station" , "PHL" ,
"2014-03-18T00:54:00" , "http://www.bytefish.de/aviation/General#node_type" , "weather_data" ,
"2014-03-18T01:54:00" , "http://www.bytefish.de/aviation/General#has_station" , "http://www.bytefish.de/aviation/WeatherStation#weather_station_PHL_KPHL" ,
"2014-03-18T01:54:00" , "http://www.bytefish.de/aviation/Weather#tmpc" , "-0.6" ,
"2014-03-18T01:54:00" , "http://www.bytefish.de/aviation/Weather#dwpc" , "-10.0" ,
"2014-03-18T01:54:00" , "http://www.bytefish.de/aviation/Weather#feelc" , "-3.244445" ,
"2014-03-18T01:54:00" , "http://www.bytefish.de/aviation/Weather#lon" , "-75.2311" ,
"2014-03-18T01:54:00" , "http://www.bytefish.de/aviation/Weather#p01i" , "0.0" ,
"2014-03-18T01:54:00" , "http://www.bytefish.de/aviation/Weather#vsby_mi" , "10.0" ,
"2014-03-18T01:54:00" , "http://www.bytefish.de/aviation/Weather#mslp" , "1020.1" ,
"2014-03-18T01:54:00" , "http://www.bytefish.de/aviation/Weather#dwpf" , "14.0" ,
"2014-03-18T01:54:00" , "http://www.bytefish.de/aviation/Weather#vsby_km" , "16.09344" ,
"2014-03-18T01:54:00" , "http://www.bytefish.de/aviation/Weather#timestamp" , "2014-03-18T01:54:00" ,
"2014-03-18T01:54:00" , "http://www.bytefish.de/aviation/Weather#feelf" , "26.16" ,
"2014-03-18T01:54:00" , "http://www.bytefish.de/aviation/Weather#alti" , "30.13" ,
"2014-03-18T01:54:00" , "http://www.bytefish.de/aviation/Weather#tmpf" , "30.92" ,
"2014-03-18T01:54:00" , "http://www.bytefish.de/aviation/Weather#lat" , "39.8683" ,
"2014-03-18T01:54:00" , "http://www.bytefish.de/aviation/Weather#sknt" , "4.0" ,
"2014-03-18T01:54:00" , "http://www.bytefish.de/aviation/Weather#relh" , "49.01" ,
"2014-03-18T01:54:00" , "http://www.bytefish.de/aviation/Weather#drct" , "70.0" ,
"2014-03-18T01:54:00" , "http://www.bytefish.de/aviation/Weather#skyl1" , "7000.0" ,
"2014-03-18T01:54:00" , "http://www.bytefish.de/aviation/Weather#metar" , "KPHL 180154Z 07004KT 10SM OVC070 M01/M10 A3013 RMK AO2 SLP201 T10061100" ,
"2014-03-18T01:54:00" , "http://www.bytefish.de/aviation/Weather#skyc1" , "OVC" ,
"2014-03-18T01:54:00" , "http://www.bytefish.de/aviation/Weather#station" , "PHL" ,
"2014-03-18T01:54:00" , "http://www.bytefish.de/aviation/General#node_type" , "weather_data" ,
"2014-03-18T02:54:00" , "http://www.bytefish.de/aviation/General#has_station" , "http://www.bytefish.de/aviation/WeatherStation#weather_station_PHL_KPHL" ,
"2014-03-18T02:54:00" , "http://www.bytefish.de/aviation/Weather#tmpc" , "-0.6" ,
"2014-03-18T02:54:00" , "http://www.bytefish.de/aviation/Weather#dwpc" , "-10.0" ,
"2014-03-18T02:54:00" , "http://www.bytefish.de/aviation/Weather#feelc" , "-4.316667" ,
Percent of Flights Cancelled by Cancellation Code
How many flights have been cancelled for my airport due to Security Delays or Weather issues? The following
SPARQL query gets the percentage of flights cancelled for an airport. The example Query binds "B" (Reason: Weather)
to ?cancellation_code.
To not have every tiny airport skewing the results, we will only use airports with more than
50,000 departures. This is done using the HAVING keyword in SPARQL.
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX general: <http://www.bytefish.de/aviation/General#>
PREFIX airport: <http://www.bytefish.de/aviation/Airport#>
PREFIX flight: <http://www.bytefish.de/aviation/Flight#>
PREFIX weather: <http://www.bytefish.de/aviation/Weather#>
PREFIX : <.>
SELECT ?airport_name ?airport_iata ?cancellation_code ((?num_cancelled_flights/?num_flights_total) * 100.0 as ?cancelledPercent)
WHERE
{
BIND("B" AS ?cancellation_code) .
?origin airport:name ?airport_name ;
airport:iata ?airport_iata .
# Number of flights at airport ?origin cancelled by ?cancellation_code:
{
SELECT ?origin ?cancellation_code (count(?cancellation_code) as ?num_cancelled_flights)
WHERE
{
?flight general:has_origin_airport ?origin .
?flight flight:cancellation_code ?cancellation_code }
GROUP BY ?origin ?cancellation_code
}
# Total Number of flights at airport ?origin:
{
SELECT ?origin (count(?origin) as ?num_flights_total)
WHERE
{
?flight general:has_origin_airport ?origin .
}
GROUP BY ?origin
}
}
HAVING (?num_flights_total > 50000)
ORDER BY DESC(?cancelledPercent)
LIMIT 10
And the results:
"airport_name" , "airport_iata" , "cancellation_code" , "cancelledPercent" ,
"Chicago O'Hare International" , "ORD" , "B" , "2.1802143285162836717345" ,
"LaGuardia" , "LGA" , "B" , "1.8585344875941888076585" ,
"Ronald Reagan Washington National" , "DCA" , "B" , "1.5704929334712168217855" ,
"Dallas/Fort Worth International" , "DFW" , "B" , "1.5213306073465105332562" ,
"Chicago Midway International" , "MDW" , "B" , "1.3525270900893775211579" ,
"Newark Liberty International" , "EWR" , "B" , "1.3411142121860161658632" ,
"Washington Dulles International" , "IAD" , "B" , "1.2565192694975644181283" ,
"Hartsfield-Jackson Atlanta International" , "ATL" , "B" , "1.2063962528970006409233" ,
"George Bush Intercontinental/Houston" , "IAH" , "B" , "1.1819068939785316571953" ,
"San Francisco International" , "SFO" , "B" , "1.1600246864757659098943" ,
TOP 10 Airports of Flights Cancelled
So what airport has the most cancelled flights? We can answer this question by taking the above query and modifying it a
little using the VALUES keyword. To have not every tiny airport skewing the results, we will only use airports with
more than 50,000 departures.
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX general: <http://www.bytefish.de/aviation/General#>
PREFIX flight: <http://www.bytefish.de/aviation/Flight#>
PREFIX airport: <http://www.bytefish.de/aviation/Airport#>
PREFIX weather: <http://www.bytefish.de/aviation/Weather#>
PREFIX : <.>
SELECT ?airport_name ?airport_iata ?num_flights_total ?num_cancelled_flights ((?num_cancelled_flights/?num_flights_total * 100.0) as ?cancelledPercent)
WHERE
{
?origin airport:name ?airport_name ;
airport:iata ?airport_iata .
# Number of flights at airport ?origin cancelled by ?cancellation_code:
{
SELECT ?origin (count(?origin) as ?num_cancelled_flights)
WHERE
{
?flight general:has_origin_airport ?origin .
# Restrict to A, B, C, D as Cancellation Code:
VALUES ?cancellation_code {"A" "B" "C" "D"} .
?flight flight:cancellation_code ?cancellation_code .
}
GROUP BY ?origin
}
# Total Number of flights at airport ?origin:
{
SELECT ?origin (count(?origin) as ?num_flights_total)
WHERE
{
?flight general:has_origin_airport ?origin .
}
GROUP BY ?origin
}
}
HAVING (?num_flights_total > 50000)
ORDER BY DESC(?cancelledPercent)
LIMIT 10
And it shows, that Chicago O'Hare International (ORD) is on Number #1 spot with around 4.7% of the flights cancelled:
"Chicago O'Hare International" , "ORD" , "287036" , "13454" , "4.6872169344611825694337" ,
"LaGuardia" , "LGA" , "106966" , "4672" , "4.3677430211469064936521" ,
"Newark Liberty International" , "EWR" , "110356" , "4814" , "4.362245822610460690855" ,
"Washington Dulles International" , "IAD" , "58097" , "2032" , "3.497598843313768352927" ,
"Ronald Reagan Washington National" , "DCA" , "72525" , "2269" , "3.12857635298173043778" ,
"Chicago Midway International" , "MDW" , "88501" , "2521" , "2.8485553835549880792307" ,
"San Francisco International" , "SFO" , "166893" , "4257" , "2.5507361003756898132336" ,
"Dallas/Fort Worth International" , "DFW" , "278309" , "6830" , "2.4541067662202803358856" ,
"John F. Kennedy International" , "JFK" , "100560" , "2319" , "2.306085918854415274463" ,
"Nashville International" , "BNA" , "55670" , "1266" , "2.2741153224357822884857" ,
Conclusion
That's it for now.
I think I only scratched the surface of Semantic Web and Linked Data technologies. It was a great experience to learn a little about SPARQL as a query language. Getting started with Apache Jena turned out to be surprisingly easy, and dotNetRDF was easy to use.